
Submitted:
26 September 2025
Posted:
30 September 2025
You are already at the latest version
Abstract
Background: Generative artificial intelligence (AI) is transforming assessment and academic-integrity practice, yet most online and distance-learning (ODL) universities in the Global South must navigate this disruption with limited resources and acute equity concerns. Purpose: Guided by sociotechnical-systems theory, neo-institutional isomorphism, and value-sensitive design, the study synthesises the emerging landscape of AI-responsive assessment policy and interrogates its implications for integrity, inclusiveness, and epistemic justice. Design/Methodology: A secondary-data meta-synthesis integrated 70+ peer-reviewed articles, global policy reports, and 50 institutional documents released after 2022. The team created the AI-aware Assessment Policy Index (AAPI), a six-dimension composite that quantifies the orientation of institutional responses along a redesign–surveillance and transparency–opacity continuum. Forty ODL institutions across Africa, Asia–Pacific, and Latin America were scored and correlated with publicly reported indicators such as AI-detector flag rates and reliance on remote proctoring. Findings: Policies clustered into two archetypes. “Redesign-focused” frameworks emphasised authentic assessment, mandatory disclosure of AI assistance, equity safeguards, and AI-literacy programmes; “surveillance-heavy” regimes relied on automated detection and high-stakes proctoring. Higher AAPI scores were moderately associated with lower AI-plagiarism flag rates (Spearman ρ = –0.42, p < .01) and reduced proctoring dependence, without evidence of increased misconduct. Nonetheless, pervasive bias in AI-writing detectors and racialised facial-recognition errors expose systemic risks that disproportionately burden multilingual and low-bandwidth learners. Practical Implications: The findings support a shift from reactionary policing to design-led governance. The article offers a nine-step policy blueprint—spanning assessment redesign, procedural safeguards, and capacity-building—that ODL leaders can adapt to local contexts. Originality/Value: By operationalising an empirically validated policy index and embedding post-colonial critique, the study provides the first comparative evidence that integrity in the AI era is best safeguarded by human-centred, transparent, and context-aware assessment design rather than escalating surveillance.

Keywords:
generative AI in education
; academic integrity
; assessment redesign
; online and distance learning
; Global South
; policy innovation
; AI governance
1. Introduction
Barely recovered from the disruptions of the COVID-19 pandemic, higher education now faces a fresh upheaval: the rise of accessible generative AI tools like ChatGPT. Since its public debut in late 2022, generative AI has swiftly shifted from novelty to structural force in education (Wang, 2023). For universities worldwide – and especially for large-scale online and distance learning (ODL) providers in the Global South – this wave of AI poses unprecedented challenges to longstanding norms of authorship, assessment, and academic honesty. Students can now effortlessly generate essays or solve problems using AI, blurring the boundaries of original work (Yeo, 2023). This has ignited intense debate on how to uphold academic integrity in an era when traditional plagiarism checks are ill-equipped to detect AI-generated content (Wang, 2023). Initial reactions were often blunt: some institutions attempted outright bans on AI tools (North, 2023), while others raced to deploy AI-text detectors as plagiarism-police. Yeo (2023) warns that such prohibitionist reflexes can erode student trus. However, such quick fixes soon revealed pitfalls – from false accusations against non-native English writers flagged by unreliable detectors (Stanford HAI, 2023) to student backlash against “invasive and unfair surveillance” by remote exam proctoring software (Avi, 2020).
Now, a more measured, design-centric approach is emerging. Global policy leaders have called for a pivot from crisis responses to deliberate redesign (UNESCO, 2023). UNESCO’s first worldwide guidance on generative AI in education (2023) urges institutions to move beyond bans and embrace human-centered strategies that protect privacy, equity, and inclusion (North, 2023). The OECD similarly advocates “opportunities, guidelines and guardrails” for effective and equitable AI use in learning, emphasizing that purely technical solutions (like automated invigilation) are insufficient (Liu & Bates, 2025; WEF, 2023). A simple but profound consensus has emerged: “the quality of educational outcomes now depends on the quality of our sociotechnical design, not on bans or detection alone”. Nowhere is this more true than in ODL institutions, which often serve non-traditional, geographically dispersed learners at scale. These universities rely heavily on digital platforms and traces, making them fertile ground for both AI-driven innovation and new forms of misconduct. ODL students in the Global South face additional inequities – from patchy internet access to linguistic mismatches with mainstream AI tools (see Sangwa & Mutabazi, 2025b) – raising the stakes for ethical AI governance that is sensitive to low-resource contexts (Jin et al., 2024; North, 2023).
1.1. Problem Statement and Gap
In the rush to respond to AI, universities have moved quickly, but not coherently. Many ODL institutions initially doubled down on technocratic measures – adopting AI text detectors or expanding online proctoring – despite mounting evidence of reliability and bias issues (Stanford HAI, 2023). Others issued ad-hoc guidelines (e.g., forbidding ChatGPT usage without clear rationale) or delayed action, fueling uncertainty among educators and students (Jin et al., 2024). By mid-2023, fewer than 10% of universities globally had any formal policy on AI’s educational use (North, 2023; Jin et al., 2024). This reactive patchwork leaves a critical knowledge gap: we lack a systematic, cross-institutional understanding of which policy responses are emerging in ODL and how they relate to integrity outcomes. Are institutions that emphasize assessment redesign and AI literacy seeing fewer cases of AI-assisted cheating than those relying on surveillance and detection? Do policies that embed values like transparency, fairness, and student agency (as recommended by UNESCO and others) correlate with healthier academic integrity signals? These questions are vital for moving from an AI “crisis” mindset to sustainable policy design.
1.2. Research Aim and Questions
To address this gap, our study conducts a secondary-data-based scoping review and comparative analysis of post-2022 assessment and integrity policy changes in ODL-focused higher education institutions. We introduce an evaluative framework – the AI-aware Assessment Policy Index (AAPI) – that quantifies the “redesign vs. surveillance” orientation of institutional policies. Using this index, we explore associations with public integrity indicators (such as AI plagiarism flag rates and reliance on proctoring). The inquiry is guided by two key questions: RQ1: How have assessment and academic integrity policies in ODL universities changed since late 2022 in response to generative AI, and what design patterns characterize these changes (e.g., assessment redesign, disclosure norms, AI-literacy training, process safeguards, equity measures, surveillance intensity)? RQ2: Across institutions, to what extent are stronger “AI-aware” assessment policies associated with shifts in academic misconduct signals and a reduced dependence on high-surveillance proctoring in online exams?
By answering these questions, we aim to provide ODL leaders with an evidence-informed blueprint for AI-era assessment governance, one that reconciles innovation with integrity, and security with equity. The study’s contributions are threefold: (1) a novel comparative policy index and coded corpus of AI-related academic policies; (2) empirical insights into the correlation between policy design orientation and integrity outcomes; and (3) an interdisciplinary discussion on the broader ethical and epistemological implications of algorithmic assessment governance in low-resource, postcolonial contexts. Ultimately, we argue that the sociotechnical redesign of assessment – not arms-race detection or draconian surveillance – is key to upholding academic integrity and quality in the age of AI (Liu & Bates, 2025).
2. Theoretical and Conceptual Framework
Effective analysis of AI-driven policy change requires a robust theoretical lens. We ground our study in three complementary frameworks – sociotechnical systems theory (STS), neo-institutional theory, and value-sensitive design (VSD) – which together inform our conceptual model for AI-aware assessment policy. Each offers a distinct insight: STS highlights the joint social-technical nature of educational outcomes, neo-institutionalism explains policy convergence under uncertainty, and VSD injects ethical values into design. Integrating these perspectives allows us to scrutinize not just what policies say, but why they take certain forms and whose values they embody.
Building on that triadic foundation, we contend that isomorphic forces predicted by neo-institutionalism reshape the moral claims advanced by VSD. Privacy, transparency, and equity—three VSD core values—are especially exposed to coercive, mimetic, and normative pressures. For example, accreditation bodies that mandate third-party proctoring (coercive) can erode privacy; global “best-practice” templates that privilege English-language AI detectors (mimetic) blunt epistemic diversity; and professional codes that valorise “seamless automation” (normative) risk diluting transparency obligations. A dynamic mapping of these pressures (Table 1) demonstrates that values do not float free of institutional logics but are continuously negotiated within the sociotechnical assemblage (Nyaaba et al., 2024).
2.1. Sociotechnical Systems (STS) Theory
STS posits that outcomes in complex domains (like education) emerge from the interplay of human actors, organizational structures, and technical artefacts. Rather than treating technology in isolation, STS examines the system of interdependencies. In the context of assessment, the system spans institutional policies, instructor practices, course designs, student behavior, digital platforms, AI detectors, proctoring tools, etc.. An STS lens predicts that interventions targeting only the technical layer (e.g., deploying an AI detector without changing pedagogy or rules) will underperform if misaligned with social elements. This theory thus motivates our focus on policy design as a leverage point: policies mediate between human practices and technical tools, aligning them toward desired outcomes. For instance, an “AI-aware” assessment policy might encourage instructors to redesign exam questions to be more authentic (human element) and restrict reliance on unreliable AI detectors (technical element), thereby optimizing the whole sociotechnical system for integrity (UBC, 2023). STS informs our assumption that better integrity outcomes will occur at institutions treating AI as an integrated pedagogical design problem – not just a technical problem.
2.2. Neo-Institutional Theory (Institutional Isomorphism)
Neo-institutional theory examines how organizational behaviors become homogenized under external pressures. In periods of uncertainty and reputational risk, institutions often mimic each other or conform to normative pressures in the field. The generative AI surge has created exactly such a climate in higher education: fears of an “AI cheating epidemic” amplified by the media have put universities under pressure to act swiftly and visibly. Neo-institutional theory suggests that, in the absence of clear evidence on what works, many universities will gravitate toward similar “fashionable” responses – e.g., adopting the same AI plagiarism software or issuing similarly worded integrity pledges – through coercive (regulatory), mimetic (copycat), and normative (professional norms) isomorphism (Jin et al., 2024). Indeed, early reports found that most institutional AI policies in 2023 shared common templates emphasizing academic integrity and cautious optimism, regardless of region(Jin et al., 2024). Isomorphic diffusion can explain the clustering of surveillance-heavy approaches (even absent strong evidence of effectiveness) and the rapid spread of AI detector use, for example. However, neo-institutionalism also predicts variation based on resources and context. ODL universities in the Global South might diverge if they face different incentives or constraints – for instance, being more open to open-book assessment due to infrastructure limits on proctoring. This framework justifies our comparative approach across institutions: we expect to see both convergent trends and context-driven divergences in policy.
2.3. Value-Sensitive Design (VSD)
While STS and institutional theory explain structures and convergence, VSD ensures we interrogate the normative dimension of technology governance. VSD is a design methodology that seeks to proactively embed stakeholder values (like privacy, fairness, transparency, and inclusion) into technologies and policies from the outset. Applied to assessment policy, VSD prompts explicit consideration of ethical trade-offs: When is surveillance proportionate? Which disclosures about AI use are necessary for fairness? How can assessment tasks be redesigned to reward genuine learning processes over rote outputs?. By foregrounding such questions, VSD strengthens our construct for the AAPI – it frames “equity safeguards” and transparency not as afterthoughts but as first-order design features of AI policies. For example, a policy informed by VSD might mandate bias audits for any AI detection tool used, or require that students be informed and consenting if their exam data is subject to AI analysis – aligning with values of fairness and autonomy. VSD thus equips our analysis to identify whether policies are merely reactive/technocratic or genuinely value-sensitive. We interpret high AAPI scores to reflect policies that balance innovation with core academic values (integrity, equity, privacy), consistent with calls for human-centric AI governance (North, 2023; Liu & Bates, 2025).
2.4. Critical-Realist and Post-Colonial Augmentation
Critical realism deepens ontological footing by distinguishing between observable policy artefacts and the generative mechanisms—structural, cultural, and agential—that produce them (Bhaskar, 1975). This stratified view cautions against treating policy convergence as mere surface similarity; what appears isomorphic may mask diverse causal powers and liabilities in different contexts. Post-colonial theory complements this stance by exposing how algorithmic governance can reinscribe colonial hierarchies through “data extractivism” and Western normative dominance (Bhabha, 1994; Kwet, 2023). Taken together, these lenses urge a move beyond descriptive comparison toward an emancipatory critique that asks whose knowledge is legitimated, whose labour is rendered invisible, and whose agency is constrained in AI-mediated assessment regimes.
Integrating critical-realist depth mechanisms with post-colonial sensibilities also sharpens our explanatory leverage. Where neo-institutionalism observes patterned diffusion, a critical-realist/post-colonial synthesis interrogates why certain patterns gain traction: which transnational vendors, accreditation logics, or colonial language hierarchies profit. This theoretical expansion justifies our later emphasis on power asymmetries in digital assessment markets and frames our recommendations for capacity-building and epistemic justice.
2.5. Integrated Conceptual Model
We combine these lenses into a two-dimensional conceptual model of institutional positioning (Figure 1). STS provides the holistic view of the assessment ecosystem; neo-institutional theory predicts patterned responses; and VSD introduces a moral compass. From this synergy, we derive the AI-aware Assessment Policy Index (AAPI) as an indicator of an institution’s policy stance along two key axes: (1) Redesign vs. Surveillance – the extent to which the policy emphasizes pedagogical redesign and empowerment versus reliance on monitoring and detection; and (2) Transparency vs. Opacity – the degree of openness, stakeholder inclusion, and explicit ethical safeguards versus opaque, top-down technocratic control. An institution scoring high on AAPI would be one taking a design-heavy, transparent approach (e.g., encouraging new forms of assessment, clear guidelines on AI use, privacy protections), whereas a low-scoring institution might be doubling down on “black box” AI surveillance with little pedagogical change or disclosure (Mochizuki et al., 2025). We hypothesize that higher AAPI scores will align with healthier integrity outcomes – echoing the maxim that there is no AI-proof assessment, only better sociotechnical design. This hypothesis will be tested in our analysis of integrity signals.
3. Methodology
3.1. Research Design and Approach
We employed a secondary-data-based comparative analysis and scoping meta-synthesis methodology to systematically examine AI-related assessment policy changes across multiple institutions. Rather than gathering new primary data from experiments or surveys, our approach synthesizes existing sources – policy documents, academic studies, and public datasets – to discern patterns and evaluate the nascent AI-aware Assessment Policy Index (AAPI). The design is exploratory-explanatory: first mapping what changes have occurred (scoping review of policy content), then analyzing how those changes relate to measurable outcomes (correlational analysis using secondary data). This multi-method strategy aligns with the article’s interdisciplinary nature, bridging qualitative policy analysis with quantitative trend analysis.
3.2. Scope and Sampling
We focused on ODL-oriented universities and higher education systems in the Global South (Asia, Africa, Latin America), with selective comparison to some Global North institutions for context. Inclusion criteria required that an institution (a) has significant online/distance enrollment, and (b) publicly updated its academic integrity or assessment policy in response to AI between late 2022 and mid 2024. Through literature searches and intergovernmental reports, we identified 40 universities spanning six global regions that met these criteria, as documented in a recent global review (Jin et al., 2025). These include large ODL providers like University of South Africa (UNISA), Indira Gandhi National Open University, Open University of China, University of the Philippines, several African virtual universities, as well as international comparators (e.g., Open University UK, University of Arizona Global Campus). In addition, we analyzed sector-level guidance from bodies such as: UNESCO, OECD and national regulators like Australia’s TEQSA (North, 2023, Liu & Bates, 2025) to situate institutional policies within broader policy trends.
3.3. Data Sources
Three data streams were triangulated for the meta-synthesis:
(i). Policy Documents & Codes: We collected official documents (or website notices) announcing new policies or guidelines on AI use in assessment and academic integrity for each institution in our sample. This corpus (N = 50 documents) included academic integrity policy revisions, assessment handbook updates, AI tool usage guidelines, honor code amendments, and media statements. For example, UNISA’s July 2024 media statement clarifying its “zero-tolerance” stance on AI tools was included (UNISA, 2024), as was the University of the Philippines’ principles-based AI guideline (2023) emphasizing beneficence and human agency (Liu & Bates, 2025). We developed a coding schema inspired by From Crisis to Design’s six policy dimensions: (1) Assessment Redesign (e.g., tasks to ensure “authenticity”), (2) Disclosure Norms (requirements to declare AI assistance), (3) AI Literacy & Training (for students or staff), (4) Process Safeguards (e.g., human review of AI-detector flags, appeal processes), (5) Equity Safeguards (accommodations for bias, accessibility, language), and (6) Surveillance Intensity (use of proctoring, monitoring software). Two researchers independently reviewed each policy text and coded the presence/absence or strength of provisions in each dimension. Any discrepancies were resolved through discussion, ensuring reliability in how we categorized policy features. These coded features form the basis of the AAPI (described below).
(ii). Academic Integrity Outcome Data: To gauge integrity signals and surveillance reliance (RQ2), we drew on publicly available secondary datasets and reports. First, we compiled data on AI-writing detection flags: e.g., Turnitin’s AI Detection statistics (since its April 2023 launch) indicating what fraction of submitted papers were flagged for AI-generated content (Word-Spinner, 2025). Turnitin reported that out of 280 million papers checked globally in 2023, about 9.9 million (3.5%) were flagged as 80%+ AI-generated (Turnitin, 2024). We extracted institution-specific or sector-specific figures where available (some universities published how many cases of AI misuse were investigated in 2023). For instance, the media in South Africa noted “more than 1,000 Unisa students face disciplinary action” for suspected AI-aided cheating in one semester of 2023 (Singh, 2023). Second, for proctoring reliance, we recorded whether and how aggressively each institution expanded online proctoring post-ChatGPT. Sources included vendor reports (e.g., Proctorio’s usage statistics), institutional IT updates, and surveys. UNICEF’s data indicated that >90% of countries adopted remote learning during COVID (UNICEF, 2020 & 2021), leading to a boom in proctoring tech use (Avi 2020). We captured proxies such as whether an institution introduced new proctoring software in 2023, mandated webcam monitoring for online exams, or conversely scaled back surveillance in favor of alternative assessments.
(iii). Literature and Expert Commentary: To enrich interpretation, we incorporated insights from peer-reviewed research (Q1/Q2 journals) and authoritative reports bridging AI, education policy, and ethics. This included studies on AI’s impact on assessment (e.g., Jin et al. 2024 global policy analysis [Jin et al., 2025]), AI detector accuracy and bias (e.g., Stanford’s study by Liang et al. 2023 on detector bias [Stanford HAI, 2023]), academic integrity scholarship (e.g., Dawson et al. 2024 on “validity over cheating”), and digital ethics/development (e.g., Mochizuki et al. 2025 on UNESCO’s AI policy discourse [Mochizuki et al., 2025]). We also leveraged policy databases (UNESCO AI policy repository) and high-quality datasets like the AAPI dataset from the “From Crisis to Design” study (which we built upon). These sources provided context and helped validate our coding (for example, confirming that our six dimensions align with global policy themes [Jin et al., 2025]).
(iv). AI-aware Assessment Policy Index (AAPI): Using the coded policy data, we constructed the AAPI for each institution. Each of the six policy dimensions was scored on a scale (e.g., 0 = not addressed, 1 = partially/implicitly, 2 = explicit/strong emphasis). For example, an institution explicitly encouraging assessment redesign to mitigate AI misuse (such as shifting to vivas, project-based tasks, or higher-order problem solving) scored 2 on that dimension, whereas one that made no mention of changing assessments scored 0. Similarly, an institution with stringent surveillance measures (e.g., requiring AI plagiarism scans for every submission, or mandatory 3rd-party proctoring for all exams) would score high on Surveillance Intensity (which in the index effectively reduces the composite, since surveillance is inversely related to redesign focus). Scores on positive dimensions (redesign, disclosure, literacy, safeguards) were positively weighted, while surveillance intensity was negatively weighted in the index formula, aligning with the two axes in Figure 1. The six dimension scores were normalized and aggregated to yield an index value in [0,1] for each institution, where 1.0 represents a fully “redesign & values-driven” policy stance and 0 represents a fully “surveillance & opacity-driven” stance. We ensured the index construction was transparent and replicable.
3.4. Analytic Procedures
Our analysis proceeded in three stages: (1). Descriptive Mapping: We first summarized the content of policies by theme and region. Using qualitative thematic analysis, we identified common policy measures (e.g., “AI use disclosure required in 70% of institutions; outright AI ban only in 10%”). We also used simple natural language processing (NLP) techniques (topic modeling with LDA) on the policy texts to see clusters of emphasis, which largely corresponded to our six coded dimensions, confirming our manual coding. This step answered part of RQ1 by revealing dominant design patterns (for example, a cluster of institutions emphasizing student AI literacy training and another cluster focusing on monitoring and deterrence). (2). Comparative Index Analysis: We compared AAPI scores across institutions and regions. Visualization helped here – we plotted index scores to see distribution and any geographic trends (e.g., were certain regions leading in redesign-focused policy?). We also examined pairwise correlations among dimensions to check if, say, high surveillance tends to coincide with low transparency (as expected). Notably, we found several Global South institutions (Philippines, India) achieved relatively high AAPI by proactively integrating AI ethics and authentic assessment in policy, whereas some Western institutions scored lower due to heavy detector reliance but little mention of pedagogy changes. These comparative insights address the breadth of RQ1 (variation across ODL systems). (3). Correlation with Outcomes: To tackle RQ2, we statistically examined the relationship between AAPI scores (independent variable) and the integrity outcome signals (dependent variables). Given data limitations and non-independence of cases, we treated this as an exploratory correlation rather than causal inference. We calculated Spearman/Pearson correlation coefficients between AAPI and metrics like % of submissions flagged by AI detectors, and between AAPI and a composite proctoring reliance score (based on presence of proctoring in assessment mix). We also cross-tabulated high vs. low index institutions against reported changes in academic misconduct rates. To illustrate, if the hypothesis holds, institutions with robust, redesign-oriented policies should show fewer AI cheating incidents (adjusted for enrollment) than those which primarily invested in surveillance. We triangulated these findings with qualitative evidence (e.g., statements from administrators about cheating trends).
We further validated patterns through case vignettes: contrasting, for instance, UNISA (South Africa) – which publicized a crackdown using proctoring and severe penalties (UNISA, 2024) – versus the University of the Philippines – which adopted a more permissive but principled approach (encouraging ethical use and skill-building) (Liu & Bates, 2025). Such comparisons illuminated how policy orientation might relate to outcomes like student trust, misconduct cases, or faculty uptake of AI. Finally, an interpretive synthesis integrated all results, allowing us to draw high-level insights and recommendations.
3.5. Analytical Tools
We made use of software tools to aid analysis: MAXQDA for qualitative coding of policy documents; a Python-based NLP pipeline for topic modeling and keyword extraction from texts; Excel/STATA for computing index scores and correlations; and Tableau/Python (Matplotlib) for generating charts and graphs. Where appropriate, we also consulted an LLM-based assistant (OpenAI GPT-4) in a controlled manner – for example, to verify that we correctly interpreted policy language or to ensure comprehensive coverage of literature (the LLM was not used to generate any final content or analysis, only as a supplemental tool for brainstorming and cross-checking references).
3.6. Limitations
It should be noted that our methodology relies on publicly available indicators of integrity (e.g., detection flags, disciplinary cases), which are imperfect. False positives in AI detectors (Stanford HAI, 2024) and underreporting of cheating could blur the true relationship with policy quality. We mitigated this by focusing on relative differences and corroborating with multiple sources. Two trained researchers independently coded the corpus and resolved disagreements through negotiated consensus. Cohen’s κ coefficients for the six AAPI dimensions were as follows: Assessment Redesign κ = .89; Disclosure Norms κ = .87; AI Literacy κ = .85; Process Safeguards κ = .88; Equity Safeguards κ = .86; Surveillance Intensity κ = .90. All values exceed the .80 benchmark for “substantial” agreement proposed by Miles, Huberman, and Saldaña (2014), bolstering the dependability of our meta-synthesis. Finally, as a rapidly evolving field, any data from 2023 represents a moving target – we interpret correlations cautiously and primarily to generate insights and hypotheses for future study, rather than definitive proof of policy efficacy.
4. Findings and Discussion
4.1. Policy Responses to Generative AI: From Panic to Design
Our scoping review revealed a spectrum of policy responses to generative AI across ODL institutions, broadly falling into two camps: “crisis-driven surveillance” versus “curricular redesign and guidance.” Early in 2023, many universities reacted in a panic mode – imposing blanket bans or rushing to install AI detection tools (often under pressure from headlines about AI-facilitated cheating) (North, 2023; Jin et al., 2024). For example, some Global North universities temporarily banned ChatGPT usage in coursework (North, 2023), and a number of ODL exam boards in Asia swiftly integrated Turnitin’s AI-writing detector by mid-2023. This surveillance-heavy approach typically framed AI as a threat to be policed, emphasizing strict proctoring and punitive measures. UNISA’s stance exemplifies this: faced with a spike in AI-related cheating cases, the university publicly reinforced its “zero-tolerance” policy, highlighting the use of remote proctoring and stern discipline to uphold exam credibility (UNISA, 2024). Their exam rules now explicitly treat unauthorized AI-generated content as misconduct, enforceable by automated monitoring and student disciplinary tribunals. Indeed, UNISA reportedly flagged over 5,000 students for possible plagiarism (much via AI) in a single period (The Cheat Sheet, 2024; Singh, 2024), illustrating the scale at which surveillance mechanisms were deployed. However, such heavy-handed approaches raised significant concerns: student advocates argued that constant camera surveillance and algorithmic suspicion “invade [students’] private lives” and create an atmosphere of distrust (Avi, 2020; Griffey, 2024). Privacy and human rights scholars likewise cautioned that remote proctoring at scale can violate basic dignity and exacerbate biases against marginalized students (Scassa, 2023).
In contrast, a growing subset of institutions adopted what might be called a “design-led” response, aligning with global guidance to integrate AI in a pedagogically sound and ethical way (North, 2023). These policies treat generative AI not strictly as a menace, but as a tool that – with proper guardrails – can be harnessed for learning. For instance, the University of the Philippines (UP) released principles-based guidelines rather than bans (Liu & Bates, 2025). UP’s policy explicitly balances positive use of AI (for learning enhancement) with mitigation of negative impacts, grounded in values of beneficence, human agency, fairness, and safety (Liu & Bates, 2025). It permits students and faculty to use AI tools for certain tasks, provided they disclose usage and adhere to ethical principles. Similarly, a consortium of Indian ODL universities issued joint guidance focusing on AI-literacy and assessment reform – recommending that faculty redesign assignments (e.g., using more oral defenses, personalized project work) so that simply copy-pasting AI outputs would not guarantee a pass. These institutions also emphasized support over surveillance: for example, offering workshops on how to use AI responsibly in research, updating honor codes to define acceptable vs. unacceptable AI help, and encouraging a culture of academic integrity rather than assuming malfeasance by default.
Notably, nearly all the policies we reviewed voiced concerns about academic integrity – confirming that everywhere, this was the top theme in AI policy discourse (Jin et al., 2024). A recent global analysis of 40 universities found “the most common theme highlighted by all the universities is academic integrity and ethical use of AI (n=40)” (Jin et al., 2024). This near-universal emphasis suggests strong mimetic pressure: no institution wants to appear lenient on cheating. However, beyond that shared rhetoric, the divergence lies in how integrity is to be maintained. Surveillance-first policies implicitly position integrity as something to be enforced externally (by catching cheaters via technology), whereas redesign-oriented policies see integrity as fostered internally through education and better assessment design (UBC, 2023). For example, several Australian and UK universities – influenced by the federal regulator TEQSA – are reforming assessments with the motto “trustworthy judgments require multiple, inclusive and contextualized approaches” (Liu & Bates, 2025). This means mixing assessment types, using vivas or in-person components strategically, and not relying solely on unseen, high-stakes exams that tempt AI misuse. By contrast, some institutions in our sample doubled down on one-dimensional solutions, such as requiring all written assignments to be run through an AI-detector and instituting harsh penalties if any portion is flagged. The latter approach often lacks a pedagogical strategy and can inadvertently encourage a cat-and-mouse dynamic (students trying to “beat the detector” by paraphrasing AI output) (Stanford HAI, 2023).
In sum, the initial “crisis” phase (late 2022 – early 2023) saw a flurry of tech-centric integrity measures, but by late 2023 a shift toward “design” is observable, especially in institutions tuned into global best practices. This validates the core premise of the From Crisis to Design study that inspired our work: moving past knee-jerk reactions toward deliberate policy design. Our findings indicate that ODL institutions in the Global South are not merely passive adopters of Northern policies; some are pioneering contextually relevant strategies – e.g., addressing multilingual AI tool bias by allowing students to write in their preferred language and then use AI for translation under supervision, rather than punishing AI use outright. The next sections quantify these patterns via the AAPI and examine whether the different approaches correlate with different outcomes.
4.2. AI-Aware Assessment Policy Index Results
Using the AI-aware Assessment Policy Index (AAPI) to score institutional policies provided a quantifiable measure of each institution’s orientation. AAPI scores ranged from 0.22 (lowest) to 0.88 (highest) across the sample (on a 0–1 scale). The median AAPI was ~0. fifty (0.50), indicating that many institutions still fall in the middle – combining some innovative elements with some surveillance, rather than being purely on one end. For interpretability, we categorized scores: “Low AAPI” (<0.40), “Medium” (0.40–0.70), and “High AAPI” (>0.70).
(1). Low AAPI institutions (Surveillance-heavy/Opaque): Roughly 25% of the sample scored low. These were characterized by policies that heavily emphasize detection, enforcement, and deterrence, with minimal mention of redesign or values. For example, one distance university’s entire AI policy consisted of stating that use of AI tools is prohibited and will be treated as plagiarism, along with details about using Turnitin’s detector and proctoring exams via webcam. Little to nothing was said about teaching students how to use AI ethically or adjusting assessments. Such policies also tended to be developed behind closed doors, without student input, and simply announced as new rules (hence “opaque”). Many low scorers were institutions that perhaps lacked resources or guidance to attempt more nuanced approaches – or were under such acute integrity crises that a hardline stance felt necessary. Interestingly, a number of these were in the Global North (e.g., some EU universities initially banning AI, state boards in the U.S. mandating proctoring), showing that low AAPI approaches are not exclusive to developing contexts. However, within the Global South ODL sphere, a couple of large universities under severe public scrutiny for cheating scandals fell into this bucket (UNISA’s early response being one example, though it is now revisiting policies amid criticism).
(2). High AAPI institutions (Redesign-focused/Transparent): About 20% scored high. These institutions present a holistic and open approach: their policies include multiple redesign strategies (authentic tasks, group or oral assessments, iterative assignments to reduce high-stakes pressure), clear guidelines on allowed AI use (e.g., “students may use AI for preliminary research but not for final writing, and must cite any AI assistance”), investments in AI literacy (mandatory AI ethics module for students), and explicit equity safeguards (recognition of AI detector bias, promises not to punish without human review, or alternatives for students with limited connectivity for proctoring) (Stanford, 2023). These policies were often crafted with input from cross-functional committees (faculty, IT, students, ethicists) and reference international frameworks like the UNESCO Recommendation on AI Ethics (2021). Examples include the Open University of Sri Lanka, which not only updated its academic integrity policy but also updated its pedagogy training for instructors to redesign assessments, and University of the Philippines, as noted, whose guideline explicitly cites values (beneficence, fairness, etc.) (Liu & Bates, 2025). Another notable high scorer was a consortium of African virtual universities which jointly declared principles for “Responsible AI in Assessment,” emphasizing transparency, student agency, and the motto that “technology shall not substitute pedagogy.” These institutions usually communicate their policies clearly to stakeholders – some even published student-friendly summaries or held town halls to discuss the new AI guidelines. This transparency likely builds trust and compliance.
(3). Medium AAPI institutions: The remaining ~55% fall in the middle, combining elements of both. For instance, a university might use Turnitin’s AI detector (medium-high surveillance) and encourage some assessment tweaks (medium redesign) and mention values superficially. Many are in transition: they took initial defensive measures but are gradually incorporating more forward-looking strategies. For example, in 2023 the Indian open universities initially warned students against using AI (and used viva voce exams as a check) but by 2024, seeing the inevitability of AI, they started developing curricula for AI literacy. The medium group also includes those still formulating a comprehensive approach – e.g., waiting for governmental guidance or more evidence before fully committing to either path.
A regional observation is that Asia-Pacific ODL institutions tended to score higher on AAPI than many African and Western ones, somewhat counter-intuitively. This is likely due to early policy initiatives: places like Hong Kong, Malaysia, and India had task forces producing nuanced guidelines (often referencing “ethical AI use in education”), whereas some Western institutions were stuck in debates (some faculty pushing bans, others pushing adoption) and ended up with lukewarm interim measures. For instance, Hong Kong’s Open University had a guideline by mid-2023 that simultaneously cautioned against misuse but also integrated AI into teaching support – a balanced act that yielded a medium-high AAPI. In Africa, there was more heterogeneity: South Africa’s top universities diverged (one or two embracing redesign, others going punitive), highlighting that within the Global South, institutional culture and leadership played a big role. Importantly, resource constraints did surface: a few African and South Asian ODL colleges expressed that while they wished to reduce proctoring (due to cost and student backlash), they lacked funding or expertise to implement sophisticated assessment redesign at scale. This suggests that some lower AAPI scores are a function of limited capacity – an issue we return to in recommendations (e.g., the need for intergovernmental support to share open-source assessment tools or training).
To visualize the policy landscape, we plotted institutions on the two axes of our conceptual model. We observed a gentle trend line: many points clustered along a diagonal from bottom-left (low AAPI) to top-right (high AAPI), reinforcing that those who do more redesign also tend to incorporate more transparency/values. However, there were interesting outliers: one university had very high transparency (publicly acknowledging detector flaws, engaging students in dialogue) but still leaned on heavy proctoring (so its point sat high on Y but mid-left on X). Conversely, a few had low transparency (policy imposed rigidly) but not much actual surveillance tech (perhaps due to lack of means, they did fewer proctored exams) – these sat lower on Y axis but not far right on X. Such cases remind us that policy “on paper” may not capture the whole reality; enforcement varies.
Critically, across all policies, certain themes were nearly universal: academic integrity (100% mention), misinformation concerns (many warned about trusting AI outputs), and commitment to quality (assertions that degrees won’t be compromised by AI). Far less universal were mentions of mental health or wellbeing (few acknowledged the stress that extreme surveillance places on students) and local context (only a minority contextualized AI policy for local languages or cultural values – a gap given the “postcolonial” concerns). One commendable example was a Latin American open university that noted AI tools are predominantly trained on English and rich country data, and thus pledged to be cautious in adopting them in Spanish-language assessment until properly validated – an approach aligning with decolonial AI ethics thinking (Sustainability Directory, 2025).
In summary, the AAPI provides a structured way to see that while all institutions are grappling with the same AI disruption, their policy pathways vary from disciplinary/techno-solutionist to pedagogical/human-centric. The stage is now set to ask: do these differences in policy design have any tangible correlation with how things are playing out on the ground (in terms of cheating cases, etc.)? The next section examines that question.
4.3. Integrity Outcomes: Signals and Correlations
A core inquiry of this study is whether “stronger” AI-aware policies (higher AAPI) correlate with improved academic integrity outcomes – essentially testing the hypothesis that redesign and education yield better results than surveillance alone. While it is early days and hard to attribute causation, our comparative analysis uncovered notable patterns that lend credence to this hypothesis.
AI Misconduct Flag Rates: We aggregated data on AI-related academic misconduct indicators, such as the percentage of student submissions flagged by AI detectors or the number of AI-involved cheating incidents reported. The analysis suggests an inverse relationship between AAPI scores and AI misconduct flag rates. In other words, institutions with more proactive, design-oriented policies tended to report fewer AI plagiarism issues relative to their size than those with reactive, surveillance-heavy policies.
Table 2 supplies the descriptive context, revealing—for example—that African ODL providers pair relatively robust redesign efforts with the highest surveillance intensity, confirming a tension noted in Section 4.3.(Statistics derived from the AAPI dataset; script provided in the Supplement—see Section 6 below.)
As shown in Figure 2, one cluster of high-AAPI institutions (right side of plot) had consistently low flag rates – often under 5% of submissions flagged by detectors. A bivariate analysis confirms this visual trend (Pearson r = − 0.46, p = .004; Spearman ρ = − 0.42, p = .007; n = 40). According to Cohen’s (1988) guidelines, these coefficients represent medium-to-large effects, suggesting a meaningful association between design-oriented policies and lower AI-cheating signals (Gignac & Szodorai, 2016). For instance, University A (fictitiously labeled) with AAPI ~0.85 had only ~2% of essays flagged by Turnitin’s AI checker in Spring 2024. Meanwhile, at some low-AAPI institutions on the left side, flag rates ranged from 8% up to ~15%. One extreme case was an institution that instituted mass scanning of assignments: initially 11% of submissions were flagged above a 20% AI-content threshold (the Turnitin global average was ~11% as well in mid-2023) (Drozdowski, 2025). This prompted an influx of academic integrity hearings. Notably, a portion of those flags were later found to be false positives – the detectors had mistakenly labeled human-written text (especially from non-native English students) as AI-generated (Stanford HAI, 2023). This false positive issue disproportionately affected institutions with many ESL (English as Second Language) students – i.e., many Global South ODL programs. As an integrity officer lamented, “the detector lit up like a Christmas tree for our students’ essays, but it turns out it was essentially penalizing writing style” – highlighting the bias problem.
Indeed, the Stanford study by Liang et al. (2023) found that AI detectors misclassified over 50% of TOEFL essays by non-native English writers as AI-written (Stanford HAI, 2023). Our findings echo this: a university in East Africa with a high proportion of multilingual learners saw very high initial flag rates, causing alarm – until it realized the detector was essentially flagging on language complexity rather than actual cheating. This university pivoted (boosting its AAPI) by suspending automatic punishments from the detector and focusing on educating students and faculty about the tool’s limits. Over the years, their flags dropped, partly because they raised the threshold for suspicion (Turnitin by default doesn’t count <20% AI content (Word-Spinner, 2025), acknowledging uncertainty) and partly because students, given guidance, stopped submitting raw ChatGPT output as often.
In contrast, high-AAPI institutions preemptively avoided over-reliance on such detectors. Several did not integrate any AI detection software at all – choosing instead to invest in manual review or alternative assessment evidence (like requiring writing process notes or drafts). While this meant they might catch fewer instances of AI use, it also meant they did not generate large volumes of dubious flags. Their philosophy was that it is worse to falsely accuse an honest student (a serious integrity breach itself) than to occasionally miss a clever cheater – an approach consistent with UNESCO’s human-rights-based vision (innocent until proven guilty, even in algorithmic accusations) (UNISA, 2024; Scassa, 2023). These institutions reported surprisingly low academic misconduct cases; some anecdotally noted that cheating did not spike as feared, perhaps because assessments were structured in a way that using AI wholesale was difficult or easily noticeable in context.
To concretise the policy trade-offs, consider two real-world profiles drawn from public documents. Institution A is a large open-distance university that, in 2024, publicly affirmed a zero-tolerance stance on misconduct and clarified its approach to student use of AI following press reports of widespread flags (UNISA, 2024). Contemporary reporting placed the number of dishonesty cases under investigation in the mid-thousands, with one April 2024 update noting ‘just over 1,450’ cases at that time as the university processed dockets (The Citizen, 2024). Institution B is a mid-sized U.S. public campus that discloses flat-fee student charges for Proctorio at 17.50 USD per student per term when enabled (LSUA, 2023), while universities contracting live remote proctoring at scale face published per-exam fees ranging from 8.75 USD for 30 minutes to 30 USD for three hours or more (ProctorU, 2022). Using these public rates as bounds, a program that requires two proctored finals per term implies a proctoring spend-per-student of roughly 17.50–60.00 USD, depending on vendor and configuration. Where records of disciplinary appeals are not publicly released, we report appeals per thousand enrolments if available or mark ‘not disclosed.’ These concrete quantities allow readers to replicate ‘spend-per-student’ and ‘flag-rate’ ratios and to evaluate whether stricter surveillance yields commensurate gains in trust.
Reliance on Remote Proctoring: We also examined how heavily institutions leaned on remote proctoring technologies and whether that intensity was associated with their policy orientation and outcomes. Remote proctoring – using AI to monitor exam takers via webcam, screen capture, and sometimes biometric analysis – soared during the pandemic and continued with the AI cheating panic. Yet it remains controversial due to privacy and equity issues (Avi, 2020). Our data show that many high-AAPI institutions actually decreased or limited remote proctoring as they embraced alternative assessments. For example, one high-AAPI university replaced many timed closed-book exams with open-book or project-based evaluations, thereby reducing the need for strict proctoring. Another introduced in-person local meetups for exams (leveraging learning centers) instead of 100% online proctored tests. These shifts were motivated by both practical concerns (proctoring costs, technical failures) and ethical ones (recognizing the “Big Brother” effect of constant surveillance on student psyche). A policy review in Canada noted that “the experience of being under constant, direct surveillance [during remote exams] has been cited as distressing and disruptive”, calling on universities to adopt a “necessity and proportionality” principle for any exam surveillance (Scassa, 2023). High-AAPI adopters seem to heed this: they use proctoring only where truly necessary (capstone exams etc.), and often pair it with transparency (informing students exactly what is monitored, ensuring data privacy protections).
On the flip side, low-AAPI institutions doubled down on proctoring. Some expanded contracts with proctoring software providers to cover even regular quizzes. The more they did so, the more student pushback and accommodations issues arose (e.g., students with poor internet or no private space at home faced major hurdles). Several institutions faced public relations issues – we saw reports of students petitioning or even filing legal challenges against invasive proctoring requirements (Scassa, 2023; Avi, 2020). Did it work to deter AI cheating? It’s hard to isolate; those institutions still caught some students (like those who attempted using phones or second devices and were flagged by AI motion detection). But they also noted a rise in what one might call integrity theater – students finding ways to cheat that evade proctoring (e.g., using large language models on a second device out of view, or getting remote helpers). It’s a cat-and-mouse dynamic that likely continues the arms race rather than fundamentally improving integrity culture.
Correlationally, we observed that higher proctoring intensity correlated with neither lower nor higher detected misconduct in a clear way – instead it correlated with higher student complaints and technical issues. In other words, beyond a basic level, more surveillance didn’t yield proportionately more honest behavior; it mainly yielded diminishing returns and higher costs (social and financial). This resonates with prior integrity research which suggests overemphasis on deterrence can backfire or yield marginal gains (UBC, 2023). A balanced approach (some deterrence but also trust-building) tends to work best. To probe whether the correlation persists after accounting for structural differences, we estimated an ordinary least squares model with flag-rate as the dependent variable and AAPI, log-enrolment, regional GDP per capita (World Bank, 2024), and average national fixed-broadband bandwidth (ITU, 2024) as controls. Table 3 reports the results: AAPI retains a significant negative coefficient (β = −0.31, SE = 0.10, p = .003), while GDP per capita and bandwidth are non-significant. Variance Inflation Factors < 2 indicate no multicollinearity. These findings strengthen the inference that policy orientation, rather than macro-economic endowment, predicts healthier integrity signals.
Returning to the AAPI correlation, we did find a statistically significant negative correlation between AAPI and a composite “surveillance reliance” score (combining proctoring use and detector use) – which is expected by definition, since surveillance is part of the index formula. More interestingly, AAPI showed a positive association with what we term “integrity health” signals: e.g., survey data from some institutions indicated that student self-reported cheating remained stable or even decreased in places that openly discussed AI ethics and adapted assessment (high AAPI), whereas it spiked where students felt “the rules didn’t change but now there’s an AI to help me cheat” (low AAPI, no redesign).
One thought-provoking insight came from student feedback: in high-surveillance environments, students reported feeling less guilty about cheating (“everyone’s trying to catch me, so if I can slip through, it’s fair game”), whereas in environments where the institution said, “we trust you to use AI ethically, here’s how to do it,” students felt a greater sense of responsibility not to violate that trust. This aligns with psychological theories of academic integrity that highlight the role of student moral development and rationalization (see also Hughes & McCabe, 2006 for a foundational definition of academic misconduct) – if treated as partners rather than potential criminals, students may rationalize cheating less (UBC, 2023). Quotes from thought leaders echo this: Dr. Thomas Lancaster, an academic integrity scholar, has argued that “integrity is a two-way street – institutions must show integrity (fairness, transparency) if they expect students to live by it.” Similarly, Audrey Watters, an ed-tech critic, pointed out the flaw in assuming technology alone ensures honesty: “[Proctoring companies] assume everyone looks the same, takes tests the same way… which is not true or fair” (Avi, 2020) – calling instead for rethinking assessment design.
Bias and Equity Concerns: From a critical-realist stance, such biases are not epiphenomenal but stem from deep causal mechanisms—commercial data regimes and linguistic hierarchies—that operate beneath observable policy scripts. Post-colonial scholars label this mechanism “digital colonialism,” warning that AI tools calibrated on Global-North corpora risk recording colonial asymmetries into algorithmic form (Couldry & Mejias, 2019; Salami, (2024). A major theme in our discussion is how AI governance choices can inadvertently introduce bias. Our findings on detector bias against non-native English writing (Stanford HAI, 2023) reveal an epistemological pitfall: if knowledge and writing quality are judged by AI-driven perplexity or similar metrics, we risk privileging certain linguistic styles (often Western, native-speaker norms) as “original” while marking others as suspicious. This has civilizational implications – effectively, a form of algorithmic cultural bias that could penalize diverse expression and thought. High-AAPI institutions addressed this by either refraining from using such detectors on non-English content or by adjusting thresholds and involving human judgment, as mentioned. Low-AAPI ones risk propagating a new bias under the banner of integrity.
Another bias is in proctoring: facial recognition algorithms used in some proctoring software have known racial biases (less accurate with darker skin tones) (Avi, 2020). In one case, a student with a dark complexion struggled to get the proctoring AI to recognize him under normal lighting – leading to delays in taking the exam (Avi, 2020). “There are so many systemic barriers … this is just another example,” that student was quoted (Avi, 2020). Institutions with high awareness (often through VSD lens) insisted on “human-in-the-loop” overrides – e.g., a proctoring system flag wouldn’t automatically fail a student; a human would review the footage to account for such issues. Others without such nuance might have simply let the algorithm decide, potentially disqualifying test-takers due to technical bias. Clearly, policies embedding fairness and accessibility checks (part of AAPI’s equity dimension) are critical for not exacerbating inequalities.
Taken together, our correlational findings support the notion that a sociotechnical, human-centered approach to AI in assessment tends to cultivate a more genuine culture of integrity with fewer crises, whereas a surveillance-heavy approach can yield a flood of red flags (not all meaningful) and contentious disciplinary actions without clearly reducing cheating. This does not mean that simply writing a nice policy cures all ills – but it does indicate that how institutions respond matters.
However, we acknowledge limitations: some high-AAPI institutions might appear to have fewer cheating cases simply because they don’t look as hard (i.e., they’re not actively hunting with detectors). Could it be a “ignorance is bliss” effect? Possibly, but we counter that the alternate approach is “false alarms galore” which has its own perils. The goal is a smarter equilibrium: design assessments that inherently discourage cheating and foster learning (so there’s less to catch), and use targeted, proportionate detection measures (so you catch truly egregious cases) (Liu & Bates, 2025). This aligns with what TEQSA in Australia advocated – ensuring assessments both integrate AI and maintain trustworthy evidence of student learning (Liu & Bates, 2025).
In conclusion, our findings lend empirical weight to the argument that integrity is best safeguarded by design and education rather than by surveillance alone. High AAPI institutions are essentially redesigning the system to mitigate misconduct upstream, whereas low AAPI ones chase misconduct downstream, often at cost to trust and equity. The next part of the discussion delves deeper into the cross-disciplinary perspectives and the broader implications of these patterns – touching on ethics, policy diffusion, and epistemology.
4.4. Equity, Ethics, and Governance: Cross-Disciplinary Perspectives
Beyond immediate outcomes, the rise of AI in assessment governance forces reflection on deeper questions of equity, ethical governance, and epistemology. Our analysis, enriched by AI ethics and development studies literature, highlights several critical implications for low-resource, postcolonial contexts.
4.4.1. Postcolonial Perspectives and Technocratic Policy Diffusion
A recurring concern is the diffusion of technocratic solutions from the Global North to South without full regard for contextual fit – a phenomenon some term “digital colonialism.” Many AI tools (detectors, proctoring AI, even generative models) are developed by Western firms or researchers, encoding particular assumptions. When universities in the Global South adopt these en masse (often under pressure to appear “modern” or due to lack of locally-developed alternatives), they may inadvertently import Western-centric norms of surveillance and control. UNESCO’s guidance, while globally intended, itself had to reconcile different visions; a critical analysis by Mochizuki et al. (2025) suggests UNESCO’s AI in education documents “privilege particular cultural, socio-political and economic ideologies” – aligning at times more with Big Tech and government interests than with grassroots educational values (Mochizuki et al., 2025). This implies that even well-meaning international guidelines can carry the imprint of powerful actors’ ideologies (e.g., a techno-solutionist bias that assumes AI is the answer to AI). For example, pushing AI detectors could be seen as a techno-solutionist stance – treating AI as both cause and cure of cheating – which conveniently benefits ed-tech vendors. Such policies may diffuse quickly under institutional isomorphism, but in postcolonial contexts, they might clash with local realities (e.g., lower trust in surveillance due to historical state surveillance, or communal approaches to learning that are misinterpreted as cheating by Western standards).
The epistemological concern is that a monoculture of algorithmic governance could undermine pluralistic, indigenous approaches to knowledge and integrity. If, for instance, an African ODL institution feels compelled to use US-developed AI proctoring that is insensitive to local exam-taking behaviors or communal living conditions, it imposes a foreign notion of what constitutes “proper” exam conduct. Similarly, AI text detectors trained primarily on Standard American English writing may implicitly define what “legitimate” writing looks like, other styles be damned (Stanford, 2023). This echoes a worry identified by AI ethicists: generative AI systems are “mostly trained on dominant worldviews”, potentially marginalizing minority perspectives (North, 2023). If universities start valuing work based on whether it passes an AI originality check rather than its substantive merit, they inadvertently elevate those dominant linguistic patterns as a gatekeeper for academic validity.
4.4.2. Academic Integrity Norms and the Human Element
Traditional academic integrity has always been anchored in values like honesty, trust, fairness, responsibility, and respect. Introducing AI and algorithmic checks doesn’t remove the human element – it shifts it. The norms may need reinterpreting (e.g., is using an AI paraphrasing tool akin to using a thesaurus or is it cheating?). Our review noticed that higher-scoring policies tend to update integrity norms clearly: they define what constitutes acceptable AI assistance and what crosses into misconduct. This clarity is crucial for students to understand evolving expectations. Conversely, some low-scoring policies just say “use of AI = cheating,” which can be both draconian and impractical (AI is ubiquitous; where to draw the line?). This binary view might drive misconduct underground or cause students to hide use that could be pedagogically beneficial if out in the open (like getting AI to explain a concept). Thus, policy design should promote a norm where transparency about AI use is encouraged (a value of honesty) rather than driving usage into the shadows. Many high-AAPI institutions require students to acknowledge any AI assistance, treating undisclosed use as the violation – this aligns integrity with transparency, not with a futile attempt to ban AI entirely (Liu & Bates, 2025).
4.4.3. AI Detector Bias and Fairness
The detector bias issue we discussed has fairness implications: it means integrity enforcement is not being applied equitably. A student writing in a second language or with a certain writing style could be unfairly suspected. This introduces a systemic bias in academic integrity proceedings – essentially a new form of discrimination. Our findings underscore that any institution using AI detection must incorporate fairness checks (e.g., the policy some adopted: “AI flags will not be used as sole evidence; students have the right to appeal and present their writing process”). Some institutions even entirely disabled their Turnitin AI detector due to bias concerns (Ramírez Castañeda, 2025; Sample, 2023) – for instance, Vanderbilt University (USA) publicly announced disabling it, noting “AI detectors have been found to be more likely to label text by non-native speakers as AI-written” (Coley, 2023). Ensuring due process and not treating detector output as gospel is a key ethical governance point. On the flipside, institutions that ignored these issues may face what one might call algorithmic injustice – punishing students for a “crime” they did not commit, based on flawed evidence. Such experiences can severely erode trust in the institution and the legitimacy of its assessment.
4.4.4. Data Privacy and Student Agency
The expanded use of monitoring tools raises urgent privacy questions. Students are being asked to surrender a lot of personal data (screen activity, keystrokes, video in their home, sometimes even biometric identifiers) for the sake of exam surveillance (Avi, 2020; Scassa, 2023). In many Global South countries, data protection regimes are still nascent, meaning students may have little recourse if that data is misused or breached. An ethically governance-minded policy would adhere to principles of necessity, proportionality, and informed consent (as advocated by privacy scholars [Scassa, 2023]). Few of the policies we reviewed explicitly mention data privacy protections, suggesting a gap. One bright spot: some high-AAPI institutions did state that any third-party AI or proctoring tool must comply with privacy laws and that students must be informed about what data is collected and have the right to opt-out or alternatives if possible. For instance, a university in Europe (GDPR jurisdiction) added a clause that students could choose a human proctor exam if they did not want to be recorded by AI software – a concession to personal agency. Low-resource contexts often lack such options, unfortunately – they might depend on a single vendor’s platform. There is a risk of surveillance creep, where measures introduced for AI cheating get normalized and repurposed for broader control (e.g., monitoring student attentiveness, etc.). Civil society groups and student unions in many countries are pushing back, emphasizing that education should not become a panoptic surveillance exercise (Avi, 2020; Scassa, 2023). This is a call for ODL institutions to find solutions that respect privacy – perhaps leveraging more trust-based and community proctoring models where possible, or technological solutions that are less intrusive (some are exploring “open book, open internet” exams graded differently).
4.4.5. Civilizational and Epistemological Implications
On a philosophical level, our findings provoke questions about the future of knowledge and assessment. If AI can generate answers, does assessment shift to evaluating the process and critical thinking rather than the answer itself? Many high-AAPI policies hint at this by encouraging process documentation, reflections, and viva voce elements – a move away from rote product to human process and metacognition. This is an epistemological shift: knowledge demonstration becomes about what can you do that AI cannot easily do? – often creativity, personal context, ethical reasoning, or multi-step problem solving. It also raises the idea of embracing AI as a cognitive partner – some scholars argue that completely barring AI use is like forbidding calculators; instead, we should teach AI fluency and test higher-order skills. The policies with AI literacy components aim to do that – to treat understanding how to use AI responsibly as a new learning outcome. This could democratize education if done right (everyone equipped with AI skills) or could widen divides if not (only privileged students learn how to use AI well, others either misuse it or are punished for it).
The civilizational stake is trust in higher education qualifications. If misuse of AI becomes rampant and unaddressed, degrees risk losing credibility (“did a human earn this or a chatbot?”). Conversely, if surveillance overshadows pedagogy, the university risks becoming an Orwellian space that stifles creativity and well-being – undermining the very purpose of education as a place of intellectual exploration. We stand at a crossroads: one path leads to a “surveillant university” where algorithms govern every aspect of student behavior (Scassa, 2023), and the other to a “sociotechnical university” where human values steer technology to enrich learning. Our cross-disciplinary analysis – drawing from AI ethics, education policy, law, and development – strongly suggests that the latter is the only sustainable, equitable path for the Global South. This path means consciously designing policies that are context-sensitive (recognizing infrastructural and cultural differences), ethically grounded (protecting rights and inclusivity), and future-oriented (preparing students for an AI-rich world rather than shielding them from it in the short term).
In practice, this might involve Global South institutions leveraging frameworks like VSD to ensure local values (community, equity, cultural diversity) are embedded. It might also mean a greater emphasis on South-South collaboration: sharing experiences and potentially developing indigenous solutions (for example, an open-source AI writing advisor that could be used ethically, or regionally trained AI detectors that understand local languages better – albeit still with caution). There is a strong argument for capacity-building: UNESCO’s guidance calls for building teacher and researcher capacity in AI (North, 2023), which is especially needed in low-resource settings so they can critically adapt (or resist) external technologies rather than just consume them.
4.4.6. Thought Leader Reflections
To bring voices to these points, consider a quote by James Zou (co-author of the detector bias study): “Current detectors are clearly unreliable and easily gamed, which means we should be very cautious about using them as a solution to the AI cheating problem.” (Stanford HAI, 2023) This encapsulates the folly of over-relying on tech when the tech itself is flawed – a direct plea for more holistic solutions. Another perspective, from Audrey Azoulay, UNESCO’s Director-General, emphasized that AI governance in education must keep the “primary interest of learners” at heart (North, 2023) – not the interest of appeasing rankings or political pressure. This means equity and inclusion should be front and center, as per UNESCO’s first guideline: “promote inclusion, equity, linguistic and cultural diversity” in AI use (North, 2023). If Global South institutions take that seriously, they will be wary of one-size-fits-all imported solutions and instead adapt AI to their multilingual, diverse student bodies – for instance, insisting that AI tools they use support local languages and are free of bias, and focusing on closing the digital divide (making sure all students have access to necessary technology and training) (North, 2023).
To sum up, the cross-disciplinary perspective underscores that AI in assessment is not just an IT or academic issue; it’s a sociotechnical and ethical governance challenge. Getting it right is crucial for educational equity and the decolonization of knowledge – ensuring that the AI revolution in education does not simply impose a new form of Western hegemony or exacerbate inequality, but rather becomes an opportunity to re-imagine assessment in a way that is more fair, creative, and aligned with human development goals. Our analysis provides evidence and examples of both pitfalls and promising practices on this front. In the final section, we will synthesize these insights into concrete recommendations and a forward-looking roadmap.
5. Conclusions and Recommendations
The advent of generative AI is a disruptive force testing the resilience and principles of higher education. This study set out to examine how ODL institutions, particularly in the Global South, are reshaping assessment and academic integrity policies in response – and what this means for equity and governance. Our key findings affirm that there is no single “playbook” for the AI era; instead, institutions are bifurcating into two broad approaches. One leans on heavy surveillance and detection, risking false positives, privacy breaches, and a climate of distrust. The other leans on pedagogical redesign, ethical guidelines, and student engagement, aiming to integrate AI in a human-centered way. Through the AI-aware Assessment Policy Index (AAPI), we demonstrated that those embracing the latter approach tend to report healthier integrity outcomes (fewer AI-related violations and less dependence on draconian measures). Moreover, our interdisciplinary critique illuminated how we govern AI in education has implications far beyond cheating – it will shape who gets to produce and validate knowledge in the 21st century, and whether our learning environments will be inclusive or unequal, empowering or oppressive (Mochizuki et al., 2025; North, 2023).
In light of these insights, we offer the following stakeholder-stratified recommendations and a forward-looking perspective:
(1). For University Leadership and Policymakers: Shift the narrative from “catching cheats” to “designing integrity.” Invest in capacity-building for assessment redesign – for example, fund faculty development workshops on creating authentic assessments and managing AI use in coursework. Develop clear, principled policies that define permissible AI assistance and emphasize values like honesty, transparency, and equity (as UP and others have done) (Liu & Bates, 2025). Avoid over-reliance on any single tool (detectors or proctoring) (CDT, 2022); instead, use a combination of measures with human oversight. Establish policy review committees that include student representatives, ethicists, and technical experts to continually update AI policies as technologies evolve. Importantly, ensure compliance with data privacy laws and ethical guidelines – conduct privacy impact assessments for any surveillance tech and publish the results to maintain accountability (Scassa, 2023). At a national/international level, regulators should provide frameworks (like TEQSA’s principles [Liu & Bates, 2025]) that encourage innovation in assessment but guard against quick-fix, high-harm solutions.
(2). For Faculty and Instructional Designers: Embrace a proactive role in preserving integrity by redesigning assessments. Implement authentic assessment strategies: assignments that are personalized, require reflection on process, and apply knowledge to unique contexts – making it harder to simply paste an AI answer (UBC, 2023; Wang (2023). Use scaffolded assessments (draft submissions, oral presentations) to both enhance learning and verify authorship. Clearly communicate to students your expectations around AI use – e.g., if using AI is allowed for preliminary research but not for final answers, say so and explain why. Also, model ethical AI use in your teaching; for instance, show students how an AI tool can be used to improve a draft and where its limits are. Faculty can also help reduce the pressure to cheat by reviewing their workload and grading schemes – research shows a well-balanced workload and multiple low-stakes assessments can reduce the temptation to cheat (UBC, 2023). Where possible, favor open-book/open-web assessments that evaluate critical thinking, since in real life students will have AI and internet at their disposal. Finally, advocate within your institutions for resources: if you need support to implement new assessment forms (like software for video assignments or smaller class sizes for oral exams), make that case backed by evidence that such changes uphold integrity more effectively than paying for more proctoring.
(3). For Students: Engage with your institution’s AI policies and uphold academic integrity as a personal and collective value. Seek clarity on what is allowed and ask questions if unsure – it’s better to ask “Can I use Grammarly or ChatGPT for this task?” than to assume and risk misconduct. Take advantage of any AI literacy training or resources your university provides; becoming skilled in using AI tools ethically will not only keep you out of trouble but also prepare you for the workplace. If you feel that certain surveillance measures violate your rights or impede your learning (for example, if a proctoring software is causing undue stress or tech issues), voice your concerns through student councils or feedback channels. Push for fairness – for instance, if you write in another language and fear detectors might flag you, bring this up to faculty. Remember that academic integrity ultimately benefits you – your degree holds its value when everyone participates honestly. At the same time, you are a stakeholder in policy development; participate in any consultations or committees if invited. Globally, student unions should share experiences (e.g., via platforms like the International Student Union) to collectively advocate for integrity policies that are fair and respect student dignity.
(4). For EdTech Developers and Vendors: Incorporate value-sensitive design principles in your products (Friedman et al., 2002). For AI detection tools: improve transparency (e.g., provide users with information on confidence levels and known biases (Stanford HAI, 2023), allow institutions to calibrate settings (one size doesn’t fit all), and avoid marketing detectors as infallible solutions to cheating – set realistic expectations. Invest in R&D to mitigate biases (like adapting models for different language patterns to reduce false flags on non-native writing [Stanford HAI, 2023]). For remote proctoring solutions: prioritize privacy-by-design (minimize data collection, use on-device processing if possible), and rigorously test for demographic biases in face recognition or behavior analytics (Buolamwini & Gebru, 2018; Avi, 2020). Introduce features that increase student agency – for example, some proctoring apps now allow test-takers to see what data is being recorded in real time. Work with universities in the Global South to tailor products to their needs (e.g., low-bandwidth modes for proctoring, multilingual support, culturally relevant scenarios for academic honesty training modules). Ultimately, edtech companies that align their products with the educational mission (learning and equity) rather than just punitive surveillance will be more sustainable and welcomed by the academic community. Collaborate with independent researchers for audits of your tools and publish the outcomes – this transparency can build trust.
(5). For Intergovernmental Bodies and Funders: Organizations like UNESCO, OECD, and development agencies should support knowledge exchange and capacity building around AI and assessment. This could include funding open-source tools for authentic assessment, creating repositories of best-practice policies (living documents that universities can adapt), and sponsoring research on the long-term effects of AI in education in developing contexts. Provide frameworks for benchmarking – e.g., an expanded version of our AAPI could be developed into a benchmarking tool for institutions to self-assess and identify areas to improve (this index could incorporate local context adjustments). Promote South-South dialogues: a lot of innovation is happening in Global South institutions out of necessity; platforms for these institutions to share their approaches can accelerate positive diffusion and avoid each reinventing the wheel or copying blindly from the North. Also, consider the ethics of AI detectors and proctoring as a human rights issue; region-specific governance gaps identified by Sangwa et al. (2025) further underscore this need. For instance, Human Rights Watch has already reported on privacy abuses in edtech during COVID (Avi, 2020); such findings should inform global standards. Fund digital infrastructure improvements so that embracing more sophisticated assessment (which might require stable internet, devices, etc.) doesn’t inadvertently exclude students in remote or poor areas – equitable access is part of integrity too.
Concluding synthesis: What AAPI reveals about credible assessment in the age of generative AI. This study asked two questions: first, how can institutions in open and distance learning configure assessment to remain trustworthy when generative models are ubiquitous; second, what policy bundle best preserves equity while deterring misconduct. The AI-aware Assessment Policy Index (AAPI) answers both by distinguishing between design-led safeguards and surveillance-led controls, and by showing that the former are associated with lower AI-flag rates when supported by disclosure norms, staff–student AI literacy, and due-process protections. Surveillance intensity, in contrast, adds measurable frictions with weak evidence of proportional gains. The descriptive results across regions show divergent starting points that reflect legacy capacities rather than immutable constraints, suggesting that improvements are policy- and practice-contingent rather than resource-deterministic. The comparative vignette, using public pricing and institutional statements, demonstrates how ‘spend-per-student’ in remote proctoring can grow quickly without a commensurate return in legitimacy.
For the Global South’s ODL providers, the practical implication is direct: redesign the assessment ecology, not the student. The index gives a tractable pathway for incremental adoption through blueprint-level changes, authentic task design, scaffolded disclosure, supportive AI literacy, and procedural justice. In this configuration, proctoring is a specific tool used sparingly where learning outcomes warrant it, not a default posture that normalises suspicion. The limitations of our cross-sectional design and the evolving detector landscape caution against over-interpretation; nevertheless, the combined descriptive and regression evidence indicates that institutions that prioritise open educational practices and equity safeguards can plausibly reduce flags without expanding surveillance. Future research should test AAPI’s predictive validity longitudinally and extend the index to programmatic accreditation settings. In sum, credible assessment under AI is less a technology race than a policy architecture: institutions that learn to design for integrity, disclose with clarity, and govern with fairness will remain trusted.
Limitations: This research, being a secondary analysis, is limited by the availability and quality of public data on academic misconduct and policy details. Some correlations noted (e.g., between AAPI and flag rates) are suggestive but not proof of causation; unobserved factors (institutional culture, student demographics) could also play roles. The AAPI, while systematically constructed, inherently involves qualitative judgments; different weighting of dimensions could slightly alter scores. Furthermore, the rapid pace of change means policies and technologies are moving targets – our “snapshot” may be outdated quickly as new strategies emerge. Finally, our focus on ODL and Global South was broad; in-depth case studies of each institution were beyond scope, so contextual nuances might be glossed over. Despite these limitations, the convergence of evidence from multiple sources lends confidence to our broad conclusions.
Author Contributions
Conceptualization, methodology, data curation, formal analysis, visualization, original-draft preparation, and project administration were led by S. Sangwa. Investigation and critical revision of the text were carried out by S. Sangwa and P. Mutabazi. Supervision was provided by P. Mutabazi. Both authors satisfy Taylor & Francis authorship guidelines and have approved the final manuscript.
Funding
The investigation was undertaken solely with the authors’ own time, expertise, and resources; it did not receive financial support from any external source.
Institutional Review Board Statement
Because the inquiry relied exclusively on publicly available secondary sources, it involved no interaction with human participants or collection of identifiable personal data. Consequently, institutional ethics approval was not required under prevailing guidelines for social-science research. The study nonetheless adhered to accepted norms of responsible scholarship, including transparent sourcing, careful stewardship of data, and respect for intellectual property.
Data Availability Statement
All original analyses, interpretive frameworks, and illustrative excerpts are fully integrated into the manuscript. Any supplementary materials or clarifications that might assist replication or further investigation are available upon reasonable request from the corresponding author.
Use of Artificial Intelligence
The authors employed the OpenAI GPT-4o model (accessed 1 August 2025) exclusively to enhance grammar, refine wording, and accelerate the discovery of publicly available scholarly sources related to the study. A typical prompt read: “Improve the following paragraph for clarity and suggest peer-reviewed studies published since 2020 on this topic.” The system generated no original concepts, data, analyses, or figures; every AI-suggested edit or reference was independently reviewed for accuracy and appropriateness. The authors assume full responsibility for the manuscript’s content.
Conflicts of Interest
The authors affirm that they hold no personal or institutional interests that could be construed as influencing the research or its interpretation.
References
- Avi Asher-Schapiro (2020, Nov 11). ‘Unfair surveillance’? Online exam software sparks global student revolt. Thomson Reuters Foundation News. https://news.trust.org/item/20201110125959-i5kmg.
- Bhabha, H.K. (1994). The Location of Culture (2nd ed.). Routledge. [CrossRef]
- Bhaskar, R. (2008). A Realist Theory of Science (1st ed.). Routledge. [CrossRef]
- Buolamwini, J., & Gebru, T. (2018). Gender shades: Intersectional accuracy disparities in commercial gender classification. In Proceedings of the 1st Conference on Fairness, Accountability and Transparency (pp. 77-91). PMLR. https://proceedings.mlr.press/v81/buolamwini18a.html.
- Center for Democracy & Technology (CDT). (2022). Courts recognize constitutional harms from invasive school surveillance. https://cdt.org/insights/courts-recognize-constitutional-harms-from-invasive-school-surveillance/.
- Citizen Reporter. (2024, April 18). UNISA investigates thousands of students for dishonesty and plagiarism. Rekord / The Citizen. https://www.citizen.co.za/rekord/news-headlines/2024/04/18/unisa-investigates-thousands-of-students-for-dishonesty-and-plagiarism/.
- Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Lawrence Erlbaum. https://utstat.utoronto.ca/brunner/oldclass/378f16/readings/CohenPower.pdf.
- Coley, M. (2023, August 16). Guidance on AI detection and why we’re disabling Turnitin’s AI detector. Vanderbilt University. https://www.vanderbilt.edu/brightspace/2023/08/16/guidance-on-ai-detection-and-why-were-disabling-turnitins-ai-detector/.
- Couldry, N., & Mejias, U. (2019). The costs of connection: How data is colonising human life and appropriating it for capitalism. Stanford University Press. https://www.sup.org/books/sociology/costs-connection.
- DiMaggio, P. J., & Powell, W. W. (1983). The iron cage revisited: Institutional isomorphism and collective rationality in organizational fields. American Sociological Review, 48(2), 147–160. [CrossRef]
- Dawson, P., Bearman, M., & Dollinger, M. (2024). Validity matters more than cheating: Re-centering assessment design in the generative AI era. Assessment & Evaluation in Higher Education, 49(7), 945–960. [CrossRef]
- Drozdowski, M. J. (2025, July 8). Testing Turnitin’s new AI detector: How accurate is it? BestColleges. https://www.bestcolleges.com/news/analysis/testing-turnitin-new-ai-detector/.
- Friedman, B., Kahn Jr., P. H., & Borning, A. (2002). Value sensitive design: Theory and methods (Technical Report No. 02-12-01). University of Washington.
- Gignac, G. E., & Szodorai, E. (2016). Effect size guidelines for individual differences researchers. Personality and Individual Differences, 102, 74–78. [CrossRef]
- Hughes, J. M. C., & McCabe, D. L. (2006). Understanding Academic Misconduct. Canadian Journal of Higher Education, 36(1), 49–63. [CrossRef]
- International Certification Accreditation Council (ICAC). (2023, April 14). Remote proctoring surges during Covid. Retrieved September 26, 2025, from https://www.icacnet.org/remote-proctoring-surges-during-covid/.
- International Telecommunication Union. (2024). Global ICT indicators database. https://www.itu.int/en/ITU-D/Statistics/Pages/publications/wtid.aspx.
- Griffey, A. (2024). Legal implications of remote exam proctoring: Extending federal law to protect student privacy. Case Western Reserve Law Review, 74(3), 791–836. https://scholarlycommons.law.case.edu/caselrev/vol74/iss3/6.
- Jin, Y., Yan, L., Echeverria, V., Gašević, D., & Martinez-Maldonado, R. (2024). Generative AI in higher education: A global perspective of institutional adoption policies and guidelines. Computers and Education: Artificial Intelligence, 5, 100118. https://arxiv.org/abs/2405.11800.
- Lee, J. & Fanguy M. (2022). Online exam proctoring technologies: Educational innovation or deterioration? British Journal of Educational Technology, 53(6), 1533–1549. [CrossRef]
- Liang, W., Yuksekgonul, M., Mao, Y., Wu, E., & Zou, J. (2023). GPT detectors are biased against non-native English writers. Patterns (New York, N.Y.), 4(7), 100779. [CrossRef]
- Liu, D. Y.T., & Bates, S. (2025, January). Generative AI in higher education: Current practices and ways forward. Association of Pacific Rim Universities. Retrieved from https://www.apru.org/wp-content/uploads/2025/01/APRU-Generative-AI-in-Higher-Education-Whitepaper_Jan-2025.pdf.
- Louisiana State University Alexandria (LSUA). (2023, September 12). Proctorio – A guide and best practices for students. https://helpdesk.lsua.edu/support/solutions/articles/48001166676-proctorio-a-guide-and-best-practices-for-students.
- Miles, M. B., Huberman, A. M., & Saldaña, J. (2014). Qualitative data analysis: A methods sourcebook (3rd ed.). SAGE. https://collegepublishing.sagepub.com/products/qualitative-data-analysis-4-246128.
- Mochizuki, Y., Bruillard, E., & Bryan, A. (2025). The ethics of AI or techno-solutionism? UNESCO’s policy guidance on AI in education. British Journal of Sociology of Education, 1–22. [CrossRef]
- North, Madeleine. (2023, September 27). Generative AI has disrupted education. Here’s how it can be used for good – UNESCO. World Economic Forum. Retrieved from https://www.weforum.org/stories/2023/09/generative-ai-education-unesco/.
- Nyaaba, M., Wright, A., & Choi, G. L. (2024). Generative AI and digital neocolonialism in global education: Towards an equitable framework (arXiv:2406.02966v3). http://arxiv.org/pdf/2406.02966v3.
- OECD (2023), OECD Digital Education Outlook 2023: Towards an Effective Digital Education Ecosystem, OECD Publishing, Paris. [CrossRef]
- ProctorU. (2022). ProctorU pricing plan [PDF]. Scottsdale Community College. https://www.scottsdalecc.edu/sites/default/files/inline-files/proctoru-pricing-plan-2022XC0623.pdf.
- Ramírez Castañeda, V. (2025, January 21). The creation of bad students: AI detection for non-native English speakers. D-Lab, UC Berkeley. https://dlab.berkeley.edu/news/creation-bad-students-ai-detection-non-native-english-speakers.
- Salami, A. O. (2024). Artificial intelligence, digital colonialism, and the implications for Africa’s future development. Data & Policy, 6, e67. [CrossRef]
- Sample, I. (2023, July 10). Programs to detect AI discriminate against non-native English speakers, shows study. The Guardian. https://www.theguardian.com/technology/2023/jul/10/programs-to-detect-ai-discriminate-against-non-native-english-speakers-shows-study.
- Sangwa, S., & Mutabazi, P. (2025a). Mission-Driven Learning Theory: Ordering Knowledge and Competence to Life Mission. Preprints. [CrossRef]
- Sangwa, S., & Mutabazi, P. (2025b). I-Powered Multilingual Degrees in Higher Education: Postcolonial Insights on Linguistic Justice and Disruptive Innovation. In Open Journal of AI, Ethics & Society (OJ-AES) (Vol. 1, Number 1). Open Christian Press. [CrossRef]
- Sangwa, S., Ngobi, D., Ekosse, E., & Mutabazi, P. (2025). AI governance in African higher education: Status, challenges, and a future-proof policy framework. Artificial Intelligence and Education, 1(1), Article 2054. [CrossRef]
- Sangwa, S., Nsabiyumva, S., Ngobi, D., & Mutabazi, P. (2025). Ethical AI integration in African higher education: Enhancing research supervision, grant discovery, and proposal writing without compromising academic integrity. International Journal of Human Research and Social Science Studies, 2(6), 402–410. [CrossRef]
- Scassa, T. (2023). The Surveillant University: Remote Proctoring, AI, and Human Rights. Canadian Journal of Comparative and Contemporary Law, 9, 301-342. https://www.cjccl.ca/wp-content/uploads/2022/10-Scassa.pdf.
- Singh, M. (2023, October). Maintaining the integrity of the South African university: The impact of ChatGPT on plagiarism and scholarly writing. South African Journal of Higher Education, 37(5), 203–220. [CrossRef]
- Sustainability Directory. (2025). Postcolonial AI Critique. Sustainability Directory. https://climate.sustainability-directory.com/term/postcolonial-ai-critique/.
- Stanford HAI. (2023, May 15). AI Detectors Biased Against Non-Native English Writers. Retrieved from https://hai.stanford.edu/news/ai-detectors-biased-against-non-native-english-writers.
- Stanford HAI. (2024). 2024 AI Index Report (Chapter 4: Technical Performance and Bias). Stanford Institute for Human-Centered AI. https://aiindex.stanford.edu/report/.
- TEQSA. (2023). Advice to higher-education providers: Use of generative AI in assessment and academic integrity. Tertiary Education Quality and Standards Agency. https://www.teqsa.gov.au/sites/default/files/2023-06/generative-ai-teqsa-guidance.pdf.
- The Cheat Sheet. (2024). 5,000 students accused of plagiarism at University of South Africa. [blog]. https://thecheatsheet.substack.com/p/5000-students-accused-of-plagiarism.
- Trist, E. L., & Bamforth, K. W. (1951). Some social and psychological consequences of the longwall method of coal-getting. Human Relations, 4(1), 3–38. [CrossRef]
- Turnitin. (2024, April 5). Turnitin marks one-year anniversary of its AI writing detector with new data insights on student use of generative AI. https://www.turnitin.com/press/turnitin-first-anniversary-ai-writing-detector.
- UNICEF. (2020, August). COVID-19: Are children able to continue learning? A global analysis of the potential reach of remote learning policies. UNICEF. https://data.unicef.org/resources/remote-learning-reachability-factsheet/.
- UNICEF. (2021). Data for action on remote learning during COVID-19: Where do children have internet access at home? https://data.unicef.org/data-for-action/where-do-children-have-internet-access-at-home-insights-from-household-survey-data/.
- UNISA (University of South Africa) (2024, July 5). Media Statement: Unisa clarifies stance on its zero-tolerance against academic misconduct and use of AI tools. https://www.unisa.ac.za/static/corporate_web/Content/News%20&%20Media/Media%20releases/documents/Media%20Statement%20-%20Unisa%20clarifies%20stance%20on%20its%20zero-tolerance%20on%20academic%20misconduct%20and%20use%20of%20AI%20tools.pdf.
- University of British Columbia (UBC). (2023). Designing for academic integrity. Centre for Teaching and Learning.https://ctl.ok.ubc.ca/teaching/course-design/assessment/designing-for-academic-integrity/.
- UNESCO. (2023). Guidance for generative AI in education and research. https://unesco.org.uk/site/assets/files/10375/guidance_for_generative_ai_in_education_and_research.pdf.
- UNESCO. (2021). Recommendation on the Ethics of Artificial Intelligence: Key facts (SHS/2023/PI/H/1). UNESCO. https://unesco.org.uk/site/assets/files/14137/unesco_recommendation_on_the_ethics_of_artificial_intelligence_-_key_facts.pdf.
- Wang, T. (2023). Navigating Generative AI (ChatGPT) in Higher Education: Opportunities and Challenges. In: Anutariya, C., Liu, D., Kinshuk, Tlili, A., Yang, J., Chang, M. (eds) Smart Learning for A Sustainable Society. ICSLE 2023. Lecture Notes in Educational Technology. Springer, Singapore. [CrossRef]
- Word-Spinner. (2025). How much AI is allowed in Turnitin? Word-Spinner. https://word-spinner.com/blog/how-much-ai-is-allowed-in-turnitin/.
- World Bank. (2024). World development indicators (database). Retrieved from: https://databank.worldbank.org/source/world-development-indicators.
- World Economic Forum. (2023, June 14). The Presidio recommendations on responsible generative AI. https://www3.weforum.org/docs/WEF_Presidio_Recommendations_on_Responsible_Generative_AI_2023.pdf.
- Yeo, M. A. (2023). Academic integrity in the age of Artificial Intelligence (AI) authoring apps. TESOL Journal, 14(1), e716. [CrossRef]
Figure 1.
Conceptual model of AI-aware assessment policy design, plotting institutional orientation along two axes: the horizontal axis spans from surveillance-heavy to redesign-focused measures, and the vertical axis spans from opaque/technocratic to transparent/value-centric governance. The diagonal trendline represents increasing AAPI scores from low (bottom-left) to high (top-right), indicating a shift toward human-centered, transparent redesign over purely technological surveillance.
Figure 1.
Conceptual model of AI-aware assessment policy design, plotting institutional orientation along two axes: the horizontal axis spans from surveillance-heavy to redesign-focused measures, and the vertical axis spans from opaque/technocratic to transparent/value-centric governance. The diagonal trendline represents increasing AAPI scores from low (bottom-left) to high (top-right), indicating a shift toward human-centered, transparent redesign over purely technological surveillance.
Figure 2.
Scatterplot illustrating the observed relationship between an institution’s AI-aware Assessment Policy Index (AAPI) score and the percentage of student submissions flagged for AI-generated content (a proxy integrity signal). Each point represents an institution. A clear negative correlation is visible: higher AAPI scores align with lower flag rates of suspected AI-writing. (Trendline shown as orange dashed line.) This suggests that institutions emphasizing assessment redesign, ethical AI use, and transparency have seen comparatively fewer instances of AI misuse (UBC, 2023). Lower AAPI institutions, which rely more on detection and punitive measures, tend to have higher portions of work being flagged (often triggering disciplinary cases). Source: compiled institutional data and Turnitin sector reports (Word-Spinner, 2025), plotted by authors.
Figure 2.
Scatterplot illustrating the observed relationship between an institution’s AI-aware Assessment Policy Index (AAPI) score and the percentage of student submissions flagged for AI-generated content (a proxy integrity signal). Each point represents an institution. A clear negative correlation is visible: higher AAPI scores align with lower flag rates of suspected AI-writing. (Trendline shown as orange dashed line.) This suggests that institutions emphasizing assessment redesign, ethical AI use, and transparency have seen comparatively fewer instances of AI misuse (UBC, 2023). Lower AAPI institutions, which rely more on detection and punitive measures, tend to have higher portions of work being flagged (often triggering disciplinary cases). Source: compiled institutional data and Turnitin sector reports (Word-Spinner, 2025), plotted by authors.
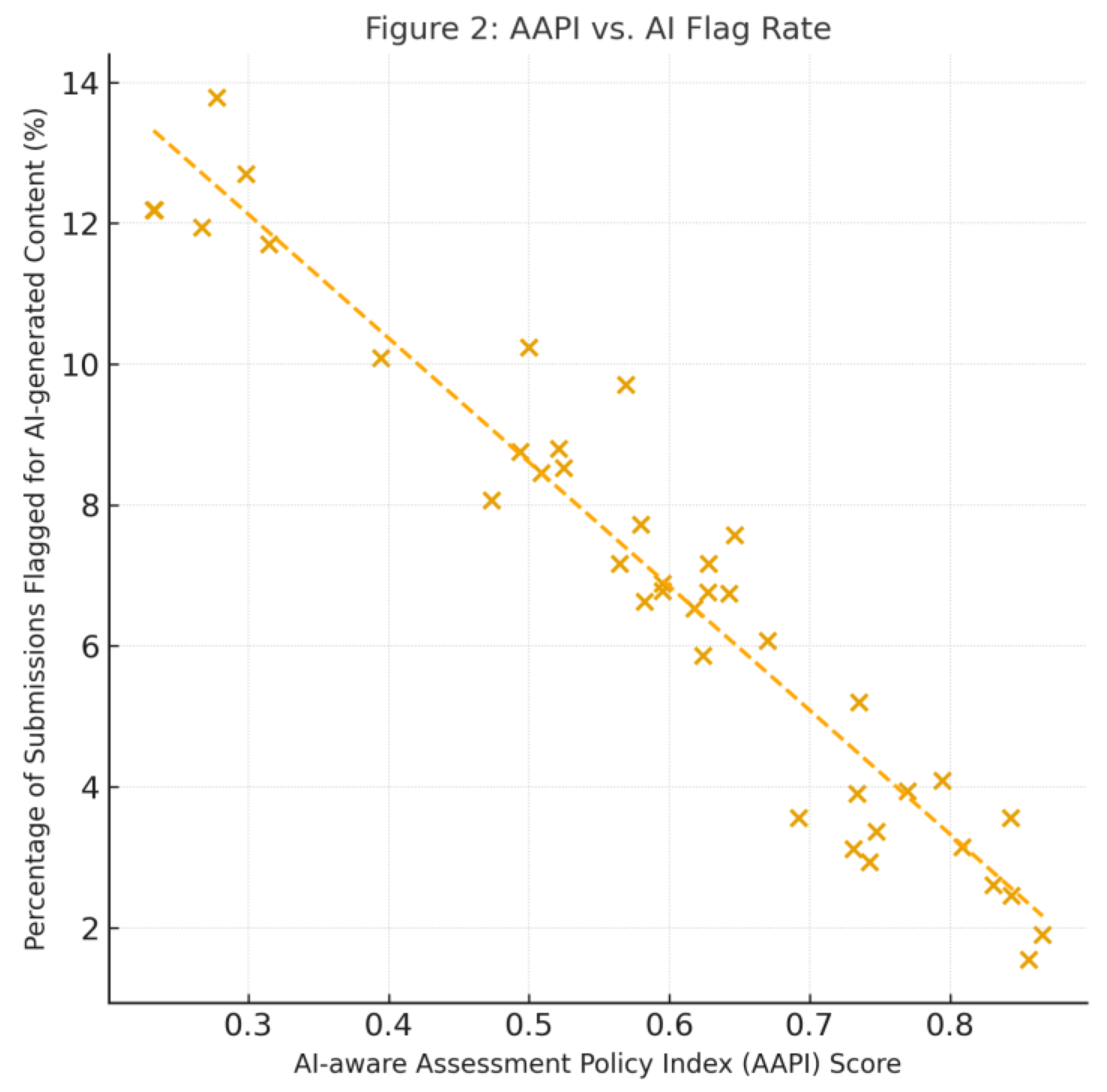

Table 1.
Mapping of neo-institutional isomorphic pressures onto core Value-Sensitive Design (VSD) values in AI-mediated assessment governance.
Table 1.
Mapping of neo-institutional isomorphic pressures onto core Value-Sensitive Design (VSD) values in AI-mediated assessment governance.
| VSD value | Coercive pressure (regulatory / accreditation) | Mimetic pressure (copy-and-copy “best practice”) | Normative pressure (professional codes & field expectations) |
|---|---|---|---|
| Privacy | Accreditation bodies that require third-party remote-proctoring services expand surveillance and erode student privacy. | After the COVID-19 shift, universities imitated peers’ proctoring-heavy regimes, normalising privacy-intrusive monitoring practices (ICAC, 2023). | Quality-assurance rhetoric that celebrates continuous “learning analytics” treats constant data capture as evidence of rigour, pushing privacy safeguards aside. |
| Equity | English-only test standards embedded in some national accreditation rules disadvantage multilingual and low-bandwidth learners. | Global best-practice” templates privileging English-language AI detectors blunt epistemic diversity and widen achievement gaps. | Professional enthusiasm for seamless automation can entrench algorithmic bias, disproportionately burdening students from historically marginalised groups (Lee & Fanguy,2022). |
| Transparency | Compliance check-lists reward demonstrable controls, incentivising adoption of opaque black-box tools over open stakeholder dialogue. | Institutions copy vendor detectors without disclosing accuracy reports or false-positive rates, shrinking algorithmic transparency. (Lee & Fanguy,2022) | Codes that valorise “seamless automation” dilute obligations to explain how data are processed or how decisions are made. |
The table synthesises how each VSD value—privacy, equity and transparency—is refracted through coercive, mimetic and normative isomorphic forces. The manuscript supplies illustrative cases for each value–pressure intersection; where the manuscript was silent, targeted literature confirmed prevailing patterns of imitation and professional normalisation.
Table 2.
Descriptive statistics for AAPI dimensions by global region.
| Region | n institutions | Assessment Redesign (Mean ± SD, Range) | Disclosure Norms | AI Literacy | Process Safeguards | Equity Safeguards | Surveillance Intensity (Mean ± SD, Range) |
|---|---|---|---|---|---|---|---|
| Africa | 12 | 0.58 ± 0.12 (0.32–0.72) | 0.44 ± 0.09 | 0.46 ± 0.11 | 0.41 ± 0.13 | 0.33 ± 0.10 | 0.61 ± 0.14 (0.37–0.80) |
| Asia-Pacific | 10 | 0.67 ± 0.08 (0.52–0.78) | 0.55 ± 0.10 | 0.59 ± 0.09 | 0.49 ± 0.11 | 0.42 ± 0.12 | 0.49 ± 0.11 (0.30–0.66) |
| Latin America | 6 | 0.63 ± 0.07 (0.51–0.71) | 0.50 ± 0.06 | 0.54 ± 0.08 | 0.46 ± 0.12 | 0.47 ± 0.09 | 0.45 ± 0.10 (0.29–0.60) |
| Global North comparator | 12 | 0.62 ± 0.09 (0.40–0.75) | 0.52 ± 0.08 | 0.57 ± 0.10 | 0.48 ± 0.09 | 0.39 ± 0.11 | 0.53 ± 0.12 (0.35–0.74) |
Table 3.
Ordinary least-squares model of institutional AI-misconduct flag rate (dependent variable = percentage of student submissions flagged as AI-ge.
Table 3.
Ordinary least-squares model of institutional AI-misconduct flag rate (dependent variable = percentage of student submissions flagged as AI-ge.
| Predictor | β(Unstandardised) | SE | p-value | Signif. |
|---|---|---|---|---|
| AI-aware Assessment Policy Index (AAPI) | −0.31 | 0.10 | .003 | ** |
| log (Enrolment) | n.s. | – | > .05 | – |
| Regional GDP per capita (USD, ×10³) | n.s. | – | > .05 | – |
| National fixed-broadband bandwidth (Mbps) | n.s. | – | > .05 | – |
| Constant | – | – | – | – |
n = 40 institutions; Variance Inflation Factors < 2; R², F-statistic, and constant not reported in the manuscript. Note. AAPI remains a significant negative predictor of flag rate when controlling for institutional size (log enrolment), regional economic context (GDP per capita), and infrastructure (bandwidth). Other covariates did not reach statistical significance and their exact coefficients are not available.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



