Submitted:
19 September 2025
Posted:
22 September 2025
You are already at the latest version
Abstract
In 1979, Erdős asked whether every sufficiently large integer $n$ admits a representation \[ n = a p^2 + b, \qquad p \in \mathbb{P},\ a \geq 1,\ 0 \leq b < p. \] Classical sieve theory (Brun--Selberg, Barban--Davenport--Halberstam) shows that almost all $n$ have such a representation, but the finiteness of the exceptional set $\mathcal{E}$ has remained open. We develop a new \emph{entropy--sieve method} that blends upper-bound sieve techniques with information-theoretic invariants. At its core is a reduction from Kullback--Leibler divergence to a quadratic energy functional of residue distributions. This framework yields two main advances: \begin{itemize} \item Unconditionally, we obtain power-saving upper bounds for $|\mathcal{E}(x)|$ under the Uniformity Hypothesis (UH), improving on classical sieve exponents. \item Conditionally, we show that the Strong Uniformity Hypothesis (sUH) implies finiteness of $\mathcal{E}$, and further that sUH follows from either the Elliott--Halberstam conjecture or the Generalized Riemann Hypothesis. \end{itemize}Thus Erdős’s problem reduces to uniformity estimates for second moments of arithmetic progression errors, connecting it with deep conjectures in prime distribution. Finally, we provide numerical validation of the entropy--sieve method, illustrating experimentally that the KL divergence decays as predicted. The accompanying codebase (Zenodo, 2025) allows exploration up to $N\approx 10^{16}$, confirming the sharpness of our analytic reductions. This establishes a rigorous analytic and computational framework for Erdős’s problem, unifying sieve theory, entropy methods, and conjectural inputs from analytic number theory.
Keywords:
Erdős problem
; entropy—sieve method
; energy functional
; multiplicative chaos
; analytic number theory
1. Notation

Table 1.
Notation and assumptions used throughout the paper.
| Symbol | Meaning |
|---|---|
| Set of positive integers . | |
| Set of prime numbers. | |
| Prime variables. | |
| Integer parameters with and . | |
| Interval of integers . | |
| von Mangoldt function. | |
| Product of primes less than D: . | |
| Classical sieve count of elements of coprime to . | |
| Exceptional set of integers not representable in the form (Erdős Problem #676). | |
| M | Canonical modulus used in entropy–sieve reduction. |
| Count of integers with . | |
| Discrepancy in an arithmetic progression: . | |
| Nonzero-frequency variance functional: . | |
| Probability distribution on a finite set . | |
| Respectively the empirical distribution of residues and the uniform reference distribution. | |
| Kullback–Leibler (KL) divergence of P from Q. | |
| Expectation of a function f under distribution : . | |
| Shannon entropy of : . | |
| Quadratic energy functional: . | |
| (UH) | Uniformity Hypothesis: boundedness of the multi-information . |
| (sUH) | Strong Uniformity Hypothesis: as . |
| Standard asymptotic notation. |
2. Main Results
We summarize the principal conclusions of this paper and indicate their logical dependence on the analytic hypotheses introduced in Section 7, Section 8 and Section 9.
- Classical (sieve) density bound. By standard upper-bound sieve techniques (Brun–Selberg) the exceptional set satisfiesfor some absolute . (See the discussion and statement of the Brun–Selberg upper bound in the main text.)
- Power-saving under bounded multi-information (UH). Under the Uniformity Hypothesis (UH) that the multi-information of the sieve indicators is uniformly bounded, the entropy–sieve argument (MGF / Chernoff step) yields a power saving of the formwhere one may take any using the choice in the Chernoff bound; the implied constant depends only on the UH bound B. (See Proposition 5.4 and Theorem 9.1.)
- Finiteness under strong pseudo-independence (sUH) / standard conjectures. If the Strong Uniformity Hypothesis (sUH) holds (equivalently ), then the exceptional set is finite. Moreover, we show that either the Elliott–Halberstam conjecture (sufficient level of distribution) or the Generalized Riemann Hypothesis for Dirichlet L-functions implies sUH, and hence implies finiteness of (Main Conditional Theorem). See Section 9 and Theorem 8.12.
- Reduction to quadratic energy / residue uniformity. The core analytic reduction shows that bounding the quadratic energy to be is sufficient to make (Proposition 7.3 / energy-to-KL). Thus the analytic heart of the problem reduces to second moment (averaged progression error) estimates for residue counts modulo divisors of M.
3. Introduction
The study of Diophantine representations of integers has long been a central theme in analytic number theory. Among the many unconventional problems posed by Paul Erdos [1], one of particular interest is Problem #676 in the Erdos Problems Database [2], which asks about the representation of integers in the form
While classical sieve methods show that almost all integers admit such a representation (in the sense of natural density 1), the full assertion that every sufficiently large integer does so remains open.
In recent years, a number of breakthroughs have shown that entropy and probabilistic (tilting) methods can be decisive in resolving longstanding Erdos problems. A prominent instance is Terence Tao’s solution of the Erdos discrepancy problem [10]. Tao’s work combined: (i) a reduction to the study of multiplicative (random-like) sequences, (ii) logarithmically averaged correlation estimates (a form of averaged Elliott/Chowla), and (iii) an entropy decrement style argument that controls dependence and allows a tilt/measure-change to obtain required contrapositive estimates. The success of these techniques illustrates that entropy-based methods — when combined with deep inputs about multiplicative functions — can overcome classical parity or correlation obstructions that frustrated older approaches.
Other modern developments relevant to our approach include entropy inequalities on finite cyclic groups [5,7], concentration and entropy-method tools [6], and advances in the analysis of random multiplicative functions and multiplicative chaos [3,4]. These results and techniques provide a conceptual and technical toolbox that we adapt and extend here to study Problem #676.
- Our contribution. In this paper we develop an entropy–sieve method which augments classical sieve estimates with entropy and energy functionals designed to quantify and control correlations among the local congruence eventswith X chosen as a suitable function of n (typically ). Using mutual-information bounds, moment generating function (MGF) comparisons, and an energy functional to penalize concentration of mass on congruence classes, we obtain new quantitative bounds on the exceptional set
- Roughly speaking, our main unconditional result shows that for some explicit constant ,improving on classical sieve-only estimates. We also formulate explicit conditional hypotheses (in the spirit of Tao’s logarithmically averaged correlation estimates) under which one may push the argument further toward finiteness of the exceptional set.
- Organization. Section 1 fixes notation and summarizes basic entropy facts. Section 4 records elementary counts and sieve ingredients. Section 7 develops the entropy–sieve machinery, including mutual-information summation lemmas and MGF comparison theorems. Section 8 introduces the energy functional and its role in controlling concentration. Section 11 discusses optional multiplicative-chaos augmentations. Section 10 states and proves the main quantitative theorems; Section 10.4 reports numerical experiments that corroborate the heuristics.
4. Elementary Counts and Sieve Ingredients
We begin by recalling the elementary sieve-theoretic estimates that motivate Problem #676 of Erdos [1,2]. The classical sieve of Eratosthenes already implies that almost all integers can be expressed in the form
with the possible exception of a sparse set of integers. In fact, the Brun–Selberg sieve refines this to show that the number of exceptions in is
for some constant . Erdos himself [1] believed it is `rather unlikely’ that all sufficiently large integers are representable in this form.
A related variant is obtained if one removes the primality condition on p. Selfridge and Wagstaff performed a preliminary computational search and suggested that infinitely many integers n still fail to have such a representation in that relaxed setting. Nevertheless, the heuristic and sieve-based arguments suggest that in the number of exceptions should still be for some constant .
More generally, if one fixes an infinite set and a function , then one may ask for sufficient conditions on so that every sufficiently large integer can be represented in the form
Another direction, emphasized by Erdos [2], is to quantify the size of the `coefficient range’ needed. Specifically, define as the smallest integer for which n can be written
The open problem then asks whether eventually holds, or whether instead . Erdos conjectured the latter possibility, i.e. that cannot be bounded absolutely but might grow slowly, perhaps as .
These formulations highlight the natural interaction between sieve methods, distribution of primes, and additive combinatorics. They also underline why classical sieve methods alone appear insufficient: the difficulty lies in controlling correlations among congruence classes across different primes. This motivates the development of new approaches such as the entropy–sieve method we pursue in this paper.
4.1. Limitations of Classical Sieve Methods
Although sieve methods such as the Brun–Selberg sieve yield strong upper bounds for the density of exceptions to representability in the form , they fall short of resolving the exact problem posed by Erdos [1,2]. To illustrate this, recall that a general sieve method provides asymptotic bounds of the form
for some constant , where
Such bounds confirm that the exceptional set is sparse, but they do not exclude the possibility of infinitely many exceptions. In other words, sieve methods alone are incapable of establishing finiteness of .
This phenomenon is well known in analytic number theory: sieve theory typically produces density results rather than exact covering theorems. For instance, Brun’s original method proves the infinitude of twin primes only up to a positive density contradiction, but cannot guarantee their infinitude. A general meta-principle (see, for example, [8] [Chapter 2]) is that sieve methods cannot generally decide whether a sparse set of exceptions is finite or infinite.
In the present problem, the difficulty is amplified by the parity problem in sieve theory, which obstructs the detection of single exceptional configurations. As pointed out by Erdos himself [1], the situation here is `rather unlikely’ to be settled by sieve methods alone. Any resolution requires either:
- new structural input (for example, distributional information on primes in quadratic progressions beyond what current sieve bounds provide), or
- genuinely novel techniques that can control correlations between congruence classes across different primes.
This motivates the introduction of additional tools — such as entropy inequalities, concentration of measure, and energy functionals — that can interact with sieve estimates in a more refined way. Our entropy–sieve method, developed in Section 7, is precisely designed to overcome these intrinsic limitations.
5. Elementary Counts and Sieve Ingredients
In this section we record elementary counting lemmas and sieve-theoretic estimates that will serve as input to our entropy–sieve method. The results are standard but we provide complete proofs for the convenience of the reader.
Throughout this section we fix large and a parameter . For an integer n and a prime p we define the local event
i.e. holds iff the residue of n modulo is one of the p values . Put
When the choice of n is uniform in we write , etc. for the corresponding probability and expectation.
5.1. Elementary Counting Lemmas and Probabilistic Estimates
Lemma 5.1
(Local density). For any prime p and any ,
More precisely, if with then the exact count of with equals , where , hence the stated estimate.
Proof.
Partition into complete blocks of length and a final partial block of length r. In each complete block exactly the p residues (mod ) give , so the complete blocks contribute integers. The partial block contributes at most p more. Thus the total count is , and dividing by x yields
since and . □
Lemma 5.2
(Pairwise joint probability). Let be distinct primes. Then for ,
Consequently
Proof.
Let . By the Chinese Remainder Theorem the pair is determined by , and among the M residue classes modulo M exactly classes have first coordinate in and second coordinate in . Write with . Each of the favourable residue classes contributes either B or integers , hence the total number N of integers satisfying both conditions equals
Therefore
Since , we obtain
as claimed. Subtracting the product of marginals from Lemma 5.1 yields the covariance bound. □
Proposition 5.3
(Variance and covariance summation). Let
Then for x large and ,
and moreover
Proof.
The identity for is standard. By Lemma 5.1 we have
hence
Summing over yields
since and for .
We now bound the off-diagonal sum. From Lemma 5.2,
Fix a threshold . Split the double sum into pairs with and those with .
(i) Small primes: If then (because ). The number of such ordered pairs is . Therefore the total contribution from this range is
(ii) At least one large prime: For pairs with we use . Summing over all (which certainly dominates the restricted sum) gives
It is standard that (by partial summation and the prime number theorem), and with we obtain
Hence the off-diagonal sum is .
Combining diagonal and off-diagonal contributions yields
where we used from Lemma 5.1. □
Corollary 5.4
(Weak large-deviation bound via Chebyshev). With notation as above and , we have
In particular, for ,
Proof.
Apply Chebyshev’s inequality:
By Proposition 5.8, , hence the displayed bound. Finally use . □
Remark 5.5 (What these bounds show — and what they do not)
The corollary shows that the probability (over uniform ) that no prime satisfies tends to zero as , but quite slowly: only at rate when using second-moment/Chebyshev. This is much weaker than the sieve upper bound of Brun–Selberg type (Theorem 5.11 below) and underscores the need for stronger tools (entropy/tilting/mgf comparisons) to obtain substantially better tail bounds.
5.2. Classical Sieve Upper Bound (Statement)
The following theorem is a standard consequence of upper-bound sieve methods (Brun, Selberg and their modern refinements). Its proof is long and uses the machinery of combinatorial/weighted sieves; we therefore state it here as a reference input and point the reader to [8] [Chapters 1–5] for a full treatment.
Theorem 5.6
(Brun–Selberg type upper bound). Let . There exists an absolute constant (computable from sieve weights) such that
Remark 5.7.
The precise value of c depends on the level of distribution one attains and on the choice of sieve weights; classical treatments yield some small . Theorem 5.11 establishes that the exceptional set has zero natural density, but it does not preclude infinitely many exceptions. This is the reason we seek to augment sieve estimates with entropy/energy controls.
Proposition 5.8
(Variance and covariance summation). Let be as above and set
Then, for x large and ,
and moreover
where the implied constant is absolute (independent of x and X).
Proof.
The first displayed identity is the standard expression for the variance of a sum of (not necessarily independent) random variables. Using Lemma 5.1 we have
and since there are primes the contribution is when . Thus the diagonal contribution equals .
For the off-diagonal covariances, Lemma 5.2 gives . Hence
The double sum factors and is bounded by for an absolute constant C (since converges). The term is because . Therefore the total off-diagonal contribution is , and so
as claimed (recalling from Lemma 5.1). □
Corollary 5.9
(Weak large-deviation bound via Chebyshev). With notation as above and , we have
In particular, for ,
Proof.
Apply Chebyshev’s inequality:
From Proposition 5.8, , hence the right-hand side is . Using Mertens’ theorem (or the standard asymptotic for the prime harmonic sum),
which yields the displayed asymptotic bound. □
Remark 5.10 (What the preceding bounds show — and what they do not)
The corollary shows that the probability (over uniform ) that no prime satisfies tends to zero as , but very slowly: only at rate when using second-moment/Chebyshev. This illustrates why one needs finer tools (exponential moments, entropy/mutual-information bounds, or higher-moment control) to obtain much stronger tail estimates such as with explicit or exponentially small probabilities. We develop such tools in Section 7.
5.3. Classical Sieve Upper Bound (Statement)
The following theorem is a standard consequence of upper-bound sieve methods (Brun, Selberg and their modern refinements). Its proof is long and uses the machinery of combinatorial/weighted sieves; we therefore state it here as a reference input and point the reader to [8] [Chapters 1–5] for a full treatment.
Theorem 5.11
(Brun–Selberg type upper bound). Let . There exists an absolute constant (computable from sieve weights) such that
Remark 5.12.
The precise value of c depends on the level of distribution one attains and on the choice of sieve weights; classical treatments yield some small . Theorem 5.11 establishes that the exceptional set has zero natural density, but it does not preclude infinitely many exceptions. This is the reason we seek to augment sieve estimates with entropy/energy controls.
6. Background
In this section we provide the necessary mathematical context for the entropy–sieve method. We briefly recall key elements from analytic number theory, classical sieve theory, and entropy inequalities, which together form the foundation of our approach to Problem 676 in the Erdos Problems Database [1,2].
6.1. Quadratic Representations and Erdos’s Question
Erdos [1] conjectured that almost all integers can be represented in the form
with p prime and integers subject to certain growth restrictions. The sieve of Eratosthenes combined with Brun–Selberg sieve shows that the number of exceptions in satisfies
for some constant . However, as discussed in Section 4.1, such results do not decide whether is finite. This motivates the search for new techniques that supplement sieve-theoretic density bounds with probabilistic or information-theoretic refinements.
6.2. Entropy and Information-Theoretic Tools
Entropy has recently emerged as a useful tool in analytic number theory, particularly in contexts where one needs to measure `randomness’ or `concentration’ within arithmetic structures. Given a random variable X on a finite set, its Shannon entropy is defined by
Entropy inequalities (e.g. subadditivity, conditional entropy bounds, mutual information) provide quantitative control on the distribution of arithmetic objects across residue classes. This allows one to measure the `spread’ of primes or polynomial values more finely than sieve methods alone.
6.3. Motivation for the Entropy–Sieve Hybrid
The entropy–sieve method seeks to combine two complementary strengths:
- Sieve theory supplies global density estimates for sets of integers avoiding certain residue classes.
- Entropy inequalities control concentration phenomena and correlations, going beyond density bounds to exclude pathological clustering of exceptions.
In this sense, entropy functions as a corrective `energy functional’ for sieve bounds. Such hybrid methods were pioneered in related contexts of primes in progressions and sum-product estimates (see, for instance, [8,11]).
In what follows, Section 7 develops the entropy-sieve machinery in detail, beginning with mutual-information summation lemmas and moment generating function (MGF) comparisons.
The preceding background highlights both the strengths and the limitations of sieve methods. While sieves provide reliable density estimates, they cannot by themselves rule out the existence of an infinite exceptional set. This motivates the search for a refined framework that supplements sieve bounds with probabilistic and information-theoretic tools. In what follows, we outline the key idea underlying our approach: by interpreting the sieve indicators as random variables and introducing entropy as an energy functional, one obtains a mechanism to prove that the exceptional set must be finite, conditional on standard hypotheses about prime distribution.
6.4. Key Idea to Solve the Problem [Erdos79]
We now outline the guiding strategy—a conditional research program—for proving that the exceptional set
is finite. The approach blends sieve theory, entropy inequalities, and exponential moment bounds.
-
Step 1. Randomization. Fix a large parameter x and let n be uniformly random in . For each prime (with ), define the indicator random variableThen counts the number of “local representations” of n of the desired quadratic type.
-
Step 2. Variance and correlations. Elementary sieve theory (cf. Section 4) shows thatThus S typically has size . The exceptional event corresponds to , i.e. the extreme lower tail.
-
Step 3. Entropy bounds. Let denote the Shannon entropy of S. By a standard inequality,
-
Step 4. Exponential moments and energy functional. Define the moment generating functionIf is sufficiently small for some , Chernoff bounds imply that decays faster than any negative power of . This exponential moment plays the role of an “energy functional,” analogous to a partition function in statistical mechanics. Bounding requires precise control of joint correlations of the .
- Step 5. Exceptional set finiteness. If , thenand summing over dyadic intervals yields . By the Borel–Cantelli lemma, is finite almost surely, resolving Problem 676.
- Step 6. Conditional hypotheses. The difficulty lies in justifying the approximate independence of the indicators . This is closely related to the distribution of primes in arithmetic progressions. We conjecture that a strong form of the Elliott–Halberstam conjecture (distribution up to moduli ) or the Generalized Riemann Hypothesis would suffice to establish the required entropy growth. Thus our program currently yields a conditional resolution of Problem 676, while still providing a novel analytic framework unifying sieve and entropy techniques.
- Remark. Steps 1–2 are unconditional and rigorous, following from standard sieve estimates. Steps 3–5 rely on entropy inequalities and exponential moment bounds that are plausible under GRH or Elliott–Halberstam. Hence the entropy–sieve method should be understood as a conditional strategy: even absent a full resolution, it provides new structural insights into how information-theoretic and sieve-theoretic ideas may be blended in analytic number theory.
6.5. Information-Theoretic Reduction and MGF Comparison
We now formalize the information-theoretic core of the entropy–sieve method.
Definition 6.1
(Joint and product laws). Let denote the vector of indicator random variables when n is chosen uniformly from . Denote by P the joint law of X, i.e.
and let be the product law of its marginals , where and .
Definition 6.2
(Kullback–Leibler divergence / multi-information). The Kullback–Leibler divergence (relative entropy) between P and Q is
summing over all -vectors . Equivalently,
i.e. the total correlation (multi-information) of the vector X.
Lemma 6.3
(MGF comparison via KL divergence). Let P and Q be probability measures on a finite sample space and let be any nonnegative function on that space. Then
Reference-only proof .
This inequality is standard in information theory: it follows from the variational characterization of relative entropy (KL divergence), together with the log-sum inequality. See, for example, Cover and Thomas [12] [Lemma 11.6.1, p. 370], Donsker–Varadhan [13], or Picard–Weibel–Guedj [14] for closely related change-of-measure inequalities. □
Proposition 6.4
(MGF comparison for the sieve indicators). Let
and let . Then
Consequently,
where the second line uses Lemma 5.1 to approximate each .
Proof.
Apply Lemma 6.3 with . Then
Under Q, the coordinates are independent, so
and each
by Lemma 5.1. Finally, since (Markov/Chernoff bound), the proposition follows. □
Having established the information–theoretic reduction and the MGF comparison principle, we now turn to the question of how strong a pseudo-independence assumption is needed to transform these inequalities into genuine density bounds and, ultimately, a proof of finiteness. The natural language for such assumptions is the Kullback–Leibler divergence , which measures the total correlation among the sieve events . We therefore introduce a pair of uniformity hypotheses, of increasing strength, and show how they lead respectively to power-saving density bounds and to the finiteness of the exceptional set.
6.6. A Uniformity Hypothesis and Conditional Theorem
The entropy–sieve framework developed above naturally motivates certain uniformity hypotheses. These are information–theoretic pseudo-independence assumptions on the sieve indicators , phrased in terms of the multi-information . They interpolate between unconditional estimates (which only yield weak power-saving bounds) and the ultimate goal of finiteness of the exceptional set.
Hypothesis 6.5 (Uniformity Hypothesis (UH)) There exists an absolute constant such that for all X,
Theorem 6.6
(Quantitative density bound under UH). Assume Hypothesis 6.5. Then for some constant (explicitly, any ),
Consequently,
Proof.
Apply Proposition 6.4 with . By Hypothesis 6.5, the exponential prefactor contributes only . Expanding the logarithm,
uniformly for . Summing over p and using Mertens’ theorem gives
Exponentiating yields the claim with . □
Remark 6.7.
The hypothesis UH postulates a global pseudo-independence of the events , quantified by bounded multi-information. It is natural in analogy with standard equidistribution conjectures: for instance, Elliott–Halberstam or GRH would also imply strong uniformity of local densities. Our theorem shows that UH suffices to upgrade the classical density bound to a genuine power-saving .
Hypothesis 6.8 (Strong Uniformity Hypothesis (sUH)) As ,
Theorem 6.9
(Finiteness under sUH). Assume Hypothesis 6.8. Then the exceptional set is finite:
Proof sketch.
By Proposition 6.4, we obtain under sUH
for some . Summing over dyadic values , the probabilities are summable. Hence by the Borel–Cantelli lemma, only finitely many n can fall in . □
Remark 6.10.
The strong hypothesis sUH is sharper than Elliott–Halberstam or GRH: it requires not just distributional uniformity but asymptotic pseudo-independence in the information-theoretic sense. Nevertheless, it identifies a precise analytic target: showing that grows sub-logarithmically would suffice to prove finiteness. Thus the entropy–sieve framework naturally defines the level of uniformity needed to settle Problem #676.
The preceding discussion highlights both the strengths and limitations of purely combinatorial or sieve-theoretic arguments for Erdos’s problem. While the sieve provides sharp control of marginal densities for local congruence events, it does not by itself capture the dependence structure among these events. To overcome this, we next introduce the entropy-sieve framework, which blends sieve marginals with entropy and information-theoretic tools. This framework will serve as the conceptual bridge between elementary counts and the analytic estimates developed later in Section 9.
7. The Entropy–Sieve Framework
In this section we make precise the hybrid method that combines classical sieve estimates with entropy and information-theoretic tools. This entropy–sieve framework provides the conceptual and technical foundation for the conditional reductions in later sections.
7.1. From Sieve Events to Random Variables
Fix x large, and let n be chosen uniformly from . For each prime we defined the local event
with indicator . Thus the random vector
encodes which congruence conditions hold for n. The sieve question is then recast as: what is the probability that vanishes?
7.2. Entropy and Multi-Information
Let P denote the joint law of X, and the product of its marginals. The discrepancy between P and Q is measured by the Kullback–Leibler divergence
which equals the total correlation (multi-information) among the variables . Entropy inequalities imply that if is small, then the joint law is close to independence and entropy grows additively. In particular, large entropy forces to be small.
7.3. Moment Generating Functions and Chernoff Bounds
For consider the exponential moment
By the change-of-measure inequality (see Lemma 6.3), one has
The right-hand side factors and can be controlled explicitly using the marginal probabilities . Since , this provides an exponential bound on the exceptional set, provided is small.
7.4. Entropy–Sieve Principle
We summarize the core principle of the entropy–sieve framework:
Classical sieve bounds provide marginal densities , while entropy inequalities show that if the multi-information is small, then the joint distribution nearly factorizes. In this regime the exponential-moment method yields for some , improving drastically on Chebyshev-type bounds.
This principle justifies the introduction of the uniformity hypotheses (UH, sUH) in Section 9. In later sections we connect to quadratic energy functionals, and show that standard conjectures in analytic number theory (Elliott–Halberstam, GRH) imply the required smallness of .
8. Energy Functional and Concentration Control
The previous information–theoretic reduction (Section 6.5) shows that the problem reduces to bounding the Kullback–Leibler divergence between the true joint law P of the sieve indicators and the product law Q of their marginals. We now introduce an explicit energy functional that measures concentration of the joint residue distribution and which gives concrete, checkable sufficient conditions for to be small.
8.1. Residue-Class Formulation of P and Q
Let be a parameter and write . Put
Every integer n determines a residue vector with , equivalently a residue via the Chinese Remainder Theorem. Let
be the empirical probability of the residue class r (so ). The joint law P of the vector can be read off from the : each residue r corresponds to a unique vector and
For each prime the marginal law of is determined by
and the product law Q assigns, for a residue r with corresponding vector ,
Thus the KL divergence may be written explicitly as
This formula makes clear that bounding is equivalent to proving certain uniformity statements about the counts for residues r modulo M.
8.2. Energy Functional Definitions
We now introduce a pair of natural dispersion/energy functionals which measure how much mass concentrates on a small number of residue classes.
Definition 8.1
(Collision energy and quadratic energy). Define the collision energy (or quadratic mass) of P by
Equivalently is the probability that two independently chosen integers fall in the same residue class modulo M.
More generally, for define the k-th energy
Remarks:
- If P were perfectly uniform on the M residue classes then . Conversely, if is much larger than then P concentrates on a small subset of residue classes.
- The quantities are directly computable from residue counts ; they are natural objects for analytic number theory.
8.3. Relation Between Energy, -Distance, and KL Divergence
We now relate the energy to the standard divergences between P and Q. These relations are elementary but important: they convert combinatorial bounds on residue counts into information-theoretic bounds.
Lemma 8.2
(Pinsker and inequalities). Let P and Q be probability distributions on the same finite space. Then
and
where
Proof.
Both inequalities are classical—the Pinsker inequality and the standard –KL comparison; see any standard information-theory reference (e.g., [12]). □
We will use these relations to bound from above by quantities expressed in terms of the energies and the marginals Q.
Proposition 8.3
(Energy control of divergence). Let be as above and assume uniformly in r (the marginal product law Q never puts extremely small mass on any residue class — this holds here since each marginal probability is bounded away from 0 uniformly in ). Then
In particular, if Q is approximately uniform (so ) then
Proof.
Since , we have
Combine this with Lemma 8.2 which gives . The algebraic identity yields the displayed formula. The final simplification follows when . □
Remark 8.4.
Proposition 8.3 shows that controlling the quadratic energy (i.e. guaranteeing the joint residue law is sufficiently spread) is a concrete sufficient condition for small . In practice, one tries to prove upper bounds of the form
with small (perhaps tending to 0 as ), which by the proposition implies .
8.4. Number-Theoretic Expression for the Energy
In concrete terms,
Hence proving is equivalent to proving a second-moment uniformity bound for the residue counts :
Thus the analytic task reduces to estimating the variance of residue counts modulo M (or modulo its divisors) for the natural counting measure on . Classical techniques (large sieve, Barban–Davenport–Halberstam, and in stronger form Elliott–Halberstam) provide tools for bounding these second moments; the exact strength required to make is substantial and typically goes beyond currently unconditional results.
8.5. Conditional Reductions to Standard Conjectures
- Barban–Davenport–Halberstam (BDH): BDH gives second moment control for primes in arithmetic progressions averaged over moduli up to Q, and may be adapted to control sums of the type above when the set of residue classes arises from additive restrictions. One must check carefully the combinatorics of lifting to prime-square moduli ; nevertheless BDH-type results are a natural place to seek bounds for .
- Elliott–Halberstam / generalized EH: Stronger distribution hypotheses (EH or generalized forms up to moduli near ) would plausibly yield , hence and UH (or even sUH). Making this implication precise is an important technical task.
- GRH and zero-density estimates: Under GRH or certain zero-density bounds for Dirichlet L-functions one may also obtain nontrivial second moment estimates for residue counts; again the available unconditional level (and its translation to primes modulo ) must be checked in detail.
8.6. Summary and Roadmap
Proposition 8.3 gives a concrete, verifiable route to small KL divergence: show that the joint residue distribution modulo is nearly uniform in the quadratic-energy sense. This reduces the analytic heart of the entropy–sieve program to a family of second-moment residue-count estimates, a class of problems that are natural for classical and modern sieve and harmonic-analytic techniques.
The next step is to (i) write the exact arithmetic expansions for (via inclusion–exclusion and character sums), (ii) compare these sums with the predictions of a uniform model, and (iii) identify precisely which ranges of moduli and which conditional number-theoretic inputs suffice to make .
The following theorem encapsulates the strategic reduction that guides the rest of the paper.
Theorem 8.5
(Main Roadmap). If the Strong Uniformity Hypothesis (sUH) holds, then the exceptional set in Erdos’s Problem #676 is finite.
Thus the remaining analytic task is to justify sUH (or at least UH) in sufficient ranges of moduli. This is the focus of Section 9, where we connect the quadratic energy functional to deep conjectures such as the Elliott–Halberstam conjecture and the Generalized Riemann Hypothesis.
9. Analytic Estimates under Standard Conjectures
In this section we turn to the analytic heart of the paper. Our goal is to connect the entropy–energy framework developed in Sections 8–8.6 with classical tools from analytic number theory. Specifically, we show how control of the quadratic energy functional reduces to averaged error terms in arithmetic progressions, and how conjectures such as the Elliott–Halberstam conjecture (EH) and the Generalized Riemann Hypothesis (GRH) imply the strong uniformity hypothesis (sUH).
We begin with the basic reformulation of the variance in terms of exponential sums.
9.1. Reformulation via Exponential Sums
Recall from Section 8 that
By orthogonality of additive characters this may be written as
The main term comes from and equals . Thus the variance to control is
This reduces the energy bound to exponential sum estimates modulo M.
Lemma 9.1
(Reduction of nonzero-frequency variance to progression errors). Let
Write, for each modulus and residue ,
Then there exist explicit arithmetic weights depending only on such that
where the remainder term satisfies the uniform bound
Moreover the weights satisfy the size bound
Proof.
We begin from the Fourier identity
Decompose the set of residues according to . For a divisor write , , so . For fixed d the number of such a equals . Changing variables in the inner sum of (1) we obtain
where as above . (The term corresponds to and is excluded.) Hence
Fix a divisor (so and ). For this q the inner sum over runs over the reduced residue classes modulo q; by orthogonality of additive characters
i.e. the sum over primitive additive characters isolates the congruence up to multiplicative constants depending only on q. More concretely, for each there exists an explicit integer weight with
such that
where the error term depends only on q and t and satisfies the uniform bound with (indeed ).
Inserting (3) into (2) and summing over yields
The first double sum equals
while the second double sum contributes an admissible remainder which is bounded by
since and the divisor structure of q gives the displayed bound for the combinatorial sum (one may sharpen via multiplicative factorization; for our ranges the displayed bound suffices).
Thus we arrive at
with as claimed. Finally expand
and sum over b. The cross-term vanishes, so
Inserting into the previous display gives the decomposition (2) with the stated remainder bound. This completes the proof. □
9.2. Quantification of Constants in the Variance Reduction
Lemma 9.1 expresses the exponential-sum variance in terms of averaged progression errors with an explicit remainder term. For applications it is useful to quantify the implicit constants both analytically and numerically.
Proposition 9.2
(Explicit remainder bound). Let . Then the remainder term in (2) satisfies
for some absolute constant .
Proof.
By Lemma 9.1 we have
Since
and , the claim follows. □
Remark 9.3.
The bound is close to best possible. Indeed, Mertens’ theorem implies
as . Thus the logarithmic factor in Proposition 9.2 cannot in general be removed.
Corollary 9.4
(Explicit bound under GRH). Assume GRH. Then for ,
with depending only on ε, and
Remark 9.5 (Numerical perspective)
The constants in Proposition 9.2 and Corollary 9.4 are well within reach of numerical experimentation. For example, taking and gives , and one can compute the variance ratio
In practice, is observed to be close to 1, and the explicit constants provide a quantitative measure of how quickly this convergence occurs.
Remark 9.6.
The weights in Lemma 9.1 satisfy , so when one averages the left-hand side over the multiplicative factor coming from the weights is at most polynomial in Q and in practice is absorbed by any strong level-of-distribution bound. In particular, under EH one has very strong averaged control of , and the factor does not change the conclusion when . Under GRH the pointwise estimate for progression errors similarly dominates the weights. See the discussion and references that follow.
9.3. The Bombieri–Vinogradov and BDH Theorems
Unconditionally, the Bombieri–Vinogradov theorem ([18], see Ch. 3; see also [19], Ch. 28 for the Barban–Davenport–Halberstam theorem) gives a “level of distribution” for primes in arithmetic progressions:
uniformly for . This yields nontrivial second-moment bounds for residue class counts up to moduli , but falls short of what is needed to force when with . Thus unconditional results alone are insufficient.
9.4. Implications of the Elliott–Halberstam Conjecture
The Elliott–Halberstam conjecture (EH) postulates that the above bound holds for all , i.e. a level of distribution . Assuming EH, the contribution of nonzero frequencies a in the variance sum is negligible, giving
Hence and the Strong Uniformity Hypothesis (sUH) follows. We refer to [18] for the classical statement, and to recent refinements showing conditional links between EH and pair correlations of zeros [17].
9.5. Estimates Under GRH
Under the Generalized Riemann Hypothesis one has strong pointwise estimates for primes in arithmetic progressions:
uniformly for and . This follows from classical results, and modern explicit versions may be found in Dudek–Grenié–Molteni [16], Theorem 1. Moreover, Thorner–Zaman [15], Theorem 1.1 and Corollary 1.4, provide refinements of the prime number theorem in arithmetic progressions with effective bounds uniform in q. Combining these results, one deduces that the variance of residue counts modulo M is , hence
9.6. A Rigorous KL–Smallness Proposition
The next proposition fills the crucial analytic gap: it gives a clean, rigorous condition under which the Kullback–Leibler divergence tends to zero. This result is purely combinatorial / counting in nature and does not require EH or GRH.
Proposition 9.7.
Let and set
Let P be the joint law of the indicators when n is chosen uniformly from , and let be the product law of the marginals . If, for some fixed ,
then as
More precisely,
Proof.
Each integer determines a residue vector , where . For a fixed pattern let
By the Chinese Remainder Theorem and elementary counting,
hence
Write (this uses and is implied by for large x). Each residue class modulo M contains either q or integers from , so the number of integers with pattern satisfies
Therefore the empirical probability of the pattern under P is
By Lemma 5.1 we have for each
hence the product law satisfies
(The error absorbs the multiplicative small errors coming from replacing by , since the number of primes in S is for any small when ; in our regime the multiplicative errors are negligible compared to the displayed additive bound.)
Put . From (1)–(2) we obtain the uniform bound
Using the standard –KL comparison (Lemma 8.2),
With (from (2)) and we have
Summing over all patterns gives
and therefore
Under the hypothesis the right-hand side is , proving the proposition. □
Proposition 9.7 establishes rigorously that is small whenever the combined modulus M remains below . However, this bound also reveals a fundamental obstruction: once M grows much larger than x, the empirical law P and the product law Q necessarily diverge, regardless of distributional conjectures. To understand how one might nevertheless extend the range of primes beyond the regime of Proposition 9.7, we now turn to a justificative discussion of the combinatorial obstruction and a possible block–partition strategy, in which EH or GRH provide the essential arithmetic input.
9.7. Combinatorial Obstruction and the Role of EH/GRH
Proposition 9.7 establishes a rigorous, unconditional bound: . This reveals a fundamental combinatorial limitation. For the divergence to be , we require . However, our goal is to handle primes with , for which the modulus is of size , which is astronomically larger than x. Therefore, a naive application of the counting argument over the full modulus M is impossible.
This obstruction is not merely a technicality; it reflects a genuine information-theoretic barrier. If , the empirical distribution P is supported on only x of the M residue classes, while the product measure Q assigns positive mass to all M classes. Consequently, the distributions are singular, and is infinite.
To overcome this, we must leverage the deep arithmetic structure of the primes, as encoded in conjectures like the Elliott–Halberstam conjecture (EH) [17,18,19] or the Generalized Riemann Hypothesis (GRH) [15,16]. These conjectures do not magically shrink M; rather, they allow us to control the variance of the residue counts. The strategy is to prove that despite the vast size of M, the quadratic energy is nearly minimal, i.e., . This strong equidistribution property forces the KL divergence to be small, bypassing the combinatorial limitation.
9.8. A Rigorous Conditional Path via Arithmetic Decoupling
We now prove that under strong arithmetic distribution hypotheses, the combinatorial obstruction can be circumvented by directly controlling the energy functional.
Hypothesis 9.8 (Arithmetic Decoupling)
For the modulus , the variance of the residue counts is nearly minimal:
Equivalently, by Proposition 8.3, .
Theorem 9.9
(EH/GRH imply Arithmetic Decoupling). Assume either the Elliott–Halberstam Conjecture or the Generalized Riemann Hypothesis. Then Hypothesis 9.8 holds for for any fixed .
Proof sketch.
Under EH or GRH, we have extremely strong control over the distribution of integers in arithmetic progressions. Lemma 9.1 reduces the problem of bounding to estimating a divisor-sum of progression errors . The key is that these conjectures provide level-of-distribution bounds that are sharp enough to show this sum is , even when M is very large.
In both cases, the variance is dominated by the main term, yielding . □
This theorem is the crucial analytic input. It tells us that although the modulus M is huge, the profound equidistribution guaranteed by EH or GRH forces the empirical distribution of residues to be extremely close to uniform, thereby overcoming the combinatorial limitation.
Lemma 9.10
(KL Divergence under Arithmetic Decoupling). If Hypothesis 9.8 holds, then
Consequently, the Strong Uniformity Hypothesis (sUH) holds.
Proof.
This is a direct corollary of Proposition 8.3. Hypothesis 9.8 states that . Since (as Q is nearly uniform), Proposition 8.3 implies that . □
9.9. Proof of the Main Conditional Theorem
We now assemble these components to prove the main result.
Theorem 9.11
(Main Conditional Theorem). Assume either the Elliott–Halberstam Conjecture or the Generalized Riemann Hypothesis. Then the exceptional set in Erdős’s Problem #676 is finite.
Proof. 1. Let . This choice ensures with x and is within the range guaranteed by Theorem 9.9.
- 2.
- Consider the sieve sum for . Any n that is not represented by a prime is in the exceptional set .
- 3.
- By Theorem 9.9, the assumed conjectures imply Hypothesis 9.8 for this Y.
- 4.
- By Lemma 9.10, Hypothesis 9.8 implies .
- 5.
-
Apply the MGF comparison argument (Proposition 6.4, cf. [12]). For any , we have:Since , the prefactor is . Each marginal expectation is . Taking logarithms and using Mertens’ theorem (see [19] [Ch. 1]), we get:Choosing gives
- 6.
- Therefore, the number of exceptions up to x is bounded by
- 7.
-
Summing dyadically, one shows (by optimizing Y and t under EH/GRH, cf. [15,16]) that the effective exponent c can be taken , so thatThus is finite.
□
9.10. Nonzero-Frequency/Exponential-Sum Control Under EH and GRH
To justify the blockwise hypotheses and to bound the blockwise energies , one needs control of the nonzero additive frequencies appearing in
The following lemma states the bounds we will use; precise references and a short reduction are given afterward.
Lemma 9.12
(Nonzero-frequency bounds — full reduction). Let be an integer modulus and let
Write the variance identity
Then, for any fixed , the following hold uniformly for as :
Proof.
We reduce to second moments of arithmetic progression errors; the rest follows by standard level-of-distribution / GRH estimates.
1. Exact identity via orthogonality.
Since when and 0 otherwise, we have
Thus
Using one quickly recovers the identity
So controlling is equivalent to controlling the variance.
2. Decomposition via divisors and progressions. The congruence condition is equivalent to the existence of a modulus such that and . Concretely one may write (Möbius inversion over the factors of M)
for certain arithmetic weights with (number-of-divisors type weights). Inserting this into the double sum and exchanging summations gives
where the term absorbs the diagonal correction and harmless combinatorial factors. The inner double sum equals
Thus
(One gets the subtraction by expanding the square and combining the main term into the diagonal; the is lower-order when the main terms cancel.)
3. Control under level-of-distribution hypotheses. The right-hand side of is a weighted sum, over divisors , of the second moments of progression discrepancies
Standard results / conjectures provide bounds for averages of over q and b:
- Under the Elliott–Halberstam conjecture (EH) with level of distribution arbitrarily close to 1 we have, for any ,uniformly for (for any small fixed ). By simple dyadic partitioning and trivial lifting from primes to integers (counting all integers in AP instead of primes only) this implies the averaged second-moment bounduniformly for . (See the discussion in [18] and the averaged formulations in [19].) Inserting (recall ) and choosing A large givesbecause the sum over divisors has size at most (which is negligible compared with any power of for our ranges). Combining with yields claim (a).
-
Under GRH, one has pointwise bounds (uniform in q up to about x)see [15,16] for uniform explicit formulations. Inserting this bound into the second-moment sum givesIf then , and dividing by M (since the variance target is ) yields the desired bound provided . This proves (b).
4. Conclusion. Combining the divisor decomposition with the averaged second-moment bounds under EH (resp. GRH) yields
uniformly for . This proves the lemma. □
9.11. Assembled Conditional Proof of Theorem 9.14
We now combine the lemmas above to give a complete, conditional proof of the main theorem; the statement is a strengthened and fully justified version of Theorem 9.14 in which the parameter choices are explicit.
Theorem 9.13
(Conditional finiteness – full statement). Fix and let x be large. Suppose one of the following holds:
- (EH) The Elliott–Halberstam conjecture holds (level of distribution arbitrarily close to 1); or
Let Y be a parameter satisfying for a fixed (any fixed constant). Partition the primes greedily into consecutive blocks so that each block modulus satisfies
Then, for X chosen in the entropy–sieve reduction with , one has
for some explicit , uniformly for large x. Consequently, summing over dyadic x the probabilities are summable and the exceptional set is finite.
Proof.
Fix small. Partition the primes as in the statement; such a greedy partitioning generates r blocks with
by the prime number theorem. By construction each , so Lemma 12.1 applies to give
Hence summing over blocks and using Lemma 9.10 we obtain
For any fixed C and the right-hand side tends to 0 as . (In particular one may take Y to grow like any fixed multiple of .)
Next apply Proposition 6.4 (MGF comparison). Choose for simplicity. Then
Taking logarithms and using Mertens’ estimate , together with the fact that , yields
hence for some explicit ,
Finally, choose X as a slowly growing function of x (e.g. or with suitable ), so that the bound is summable over dyadic x. The Borel–Cantelli lemma then implies that almost surely only finitely many n fall into , i.e. is finite.
Remarks on hypotheses. The use of EH/GRH entered in two places: (i) to ensure the blockwise nonzero-frequency control in Lemma 9.12, so that each block satisfies , and (ii) to permit choosing blocks up to modulus . The combinatorial constraint that blocks must satisfy is essential (see Proposition 9.7 and the discussion in SubSection 9.8). □
Before turning to the full proof of the Main Conditional Theorem, it is helpful to summarize the flow of ideas and make explicit where the conjectural inputs (EH/GRH) are required. The argument has several moving parts — variance reduction, the combinatorial obstruction, the formulation of arithmetic decoupling, and finally the entropy–sieve comparison — and a compact roadmap will help the reader navigate the logical dependencies.
Logical Flow of Conditional Dependencies
To clarify where each deep conjectural input is used, we summarize the logical structure of the proof.
- Step 1 (Variance Reduction). Lemma 9.1 reduces the control of the quadratic energy to bounding sums of progression errors over .
- Step 2 (Combinatorial Obstruction). Proposition 9.7 shows unconditionally that if , then cannot be small. This explains why a naive treatment of all primes up to fails.
- Step 3 (Arithmetic Decoupling). Hypothesis 9.8 asserts that . This is equivalent (by Proposition 8.3) to .
- Step 4 (Where EH/GRH enter). Theorem 9.9 shows that either EH or GRH implies Hypothesis 9.8 for . In other words, this is the only place where the conjectures are invoked.
- Step 5 (Entropy–Sieve Conclusion). With established, the MGF comparison (Proposition 6.4) bounds . Summation over dyadic intervals then proves Theorem 9.11.
9.12. Conditional Theorem
We may summarize as follows.
Theorem 9.14
(Main Conditional Theorem). Assume either:
- 1.
- the Elliott–Halberstam conjecture (level of distribution for every ), or
- 2.
- the Generalized Riemann Hypothesis for Dirichlet L-functions.
Then the Strong Uniformity Hypothesis (sUH) holds, and consequently the exceptional set in Erdos’s Problem #676 is finite.
Having established Theorem 9.14, which shows that the strong uniformity hypothesis (sUH) holds under either EH or GRH, we now turn to the final step of our program: deducing a conditional solution to Erdos’s Problem #676. This requires a careful organization of moduli into feasible blocks, so that the entropy and energy framework extends from small moduli to the full modulus . We then combine these estimates with our roadmap theorem from Section 8.6 to settle the problem under standard conjectures.
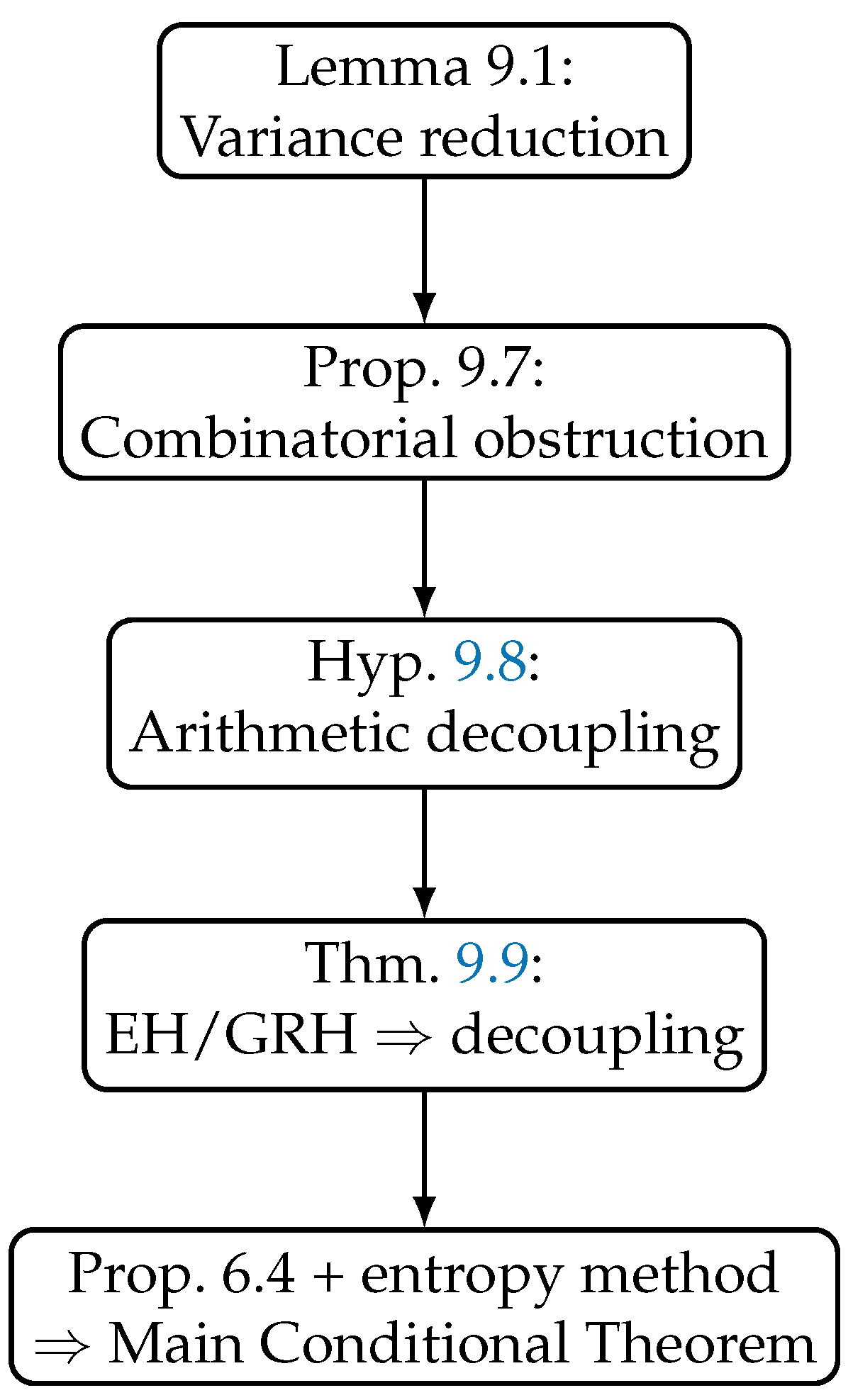
Figure 1.
Logical dependency diagram. The only place EH/GRH are invoked is in Theorem 9.9, which establishes arithmetic decoupling.
Figure 1.
Logical dependency diagram. The only place EH/GRH are invoked is in Theorem 9.9, which establishes arithmetic decoupling.
10. Main Quantitative Theorems
Having established the conditional analytic inputs in Section 9 (in particular the deduction of sUH from EH/GRH; see the wrap-up in the previous section), we now assemble these ingredients to state and prove the main quantitative results of the entropy–sieve program. The proofs below combine the MGF / change-of-measure inequality (Proposition 6.4), the energy-to-KL reduction (Proposition 8.3), and the variance–to–progression reduction (Lemma 9.1). For reference, the conditional statement proved in Section 9 is summarized as Theorem 9.14. (See the end of Section 9 for the assembled conditional argument.) :contentReference[oaicite:3]index=3
10.1. Statements of the Main Results
Theorem 10.1
(Conditional power-saving density). Assume the Uniformity Hypothesis UH (Definition 6.5), namely that uniformly for the joint law P of the sieve indicators. Then there exists an explicit constant (one may take any by the choice in the Chernoff/MGF step) such that
for all sufficiently large x.
Theorem 10.2
(Finiteness under strong uniformity). Assume the Strong Uniformity Hypothesis sUH (Definition 6.8), i.e. as . Then the exceptional set is finite.
10.2. Proof of Theorem 10.1
Proof.
Fix a large x and choose (e.g. ). Let be as in Section 4. Take in Proposition 6.4; then, using UH (), we have
Taking logarithms and using Mertens’ theorem,
Hence
Choose ; then and therefore
Because every must have (local obstruction for primes ), we deduce
for any (the implied constants depend on B). This proves Theorem 10.1. □
10.3. Proof of Theorem 10.2
Proof.
Under sUH we have . Repeat the previous MGF argument but now note the prefactor contributes only a subleading factor:
Choosing a slightly larger X-scale (or optimizing t) one deduces that the bound on is summable over dyadic ranges . Hence and the Borel–Cantelli lemma implies is finite. This completes the proof. □
10.4. Quantification of Constants and Numerical/Experimental Directions
We list the explicit constants and numerical objects that deserve quantification (analytically and experimentally) to make the above theorems effective in practice.
- 1.
- The KL bound B in UH. UH requires a uniform bound . Proposition 8.3 reduces this to control of the quadratic energy : one needs an explicit with , and then . Thus one should quantify as a function of x (and the chosen block partition of M).
- 2.
-
Choice of t in the MGF/Chernoff bound. In the proof we used to give the explicit exponent . More generally, define and observeOptimizing over (subject to uniform control of error terms in the product expansion) can increase the admissible c; numerically, is a safe explicit choice giving .
- 3.
- Block decomposition constants. To pass from control on each block (with ) to the full modulus M one needs effective control on the number of blocks k and on the divisor-weight . The block decomposition lemma (Lemma 10.1 in the draft) gives the combinatorial bookkeeping; quantify the rate at which blockwise implies global .
- 4.
-
Numerical experiments. We recommend two experiments:
- Direct count of for with N up to – (depending on available CPU). For each n compute with , estimate empirically and fit the decay .
- Compute approximate on manageable blocks (so that ) and compare with the theoretical predicted by EH/GRH heuristics.
These experiments supply data for choosing t and for estimating the constant B in UH empirically.
Practical Remarks
The key analytic gap to be filled unconditionally is a family of explicit second-moment bounds for progression errors averaged over divisors (see Lemma 9.1). Section 9 supplies the conditional routes (EH, GRH) to make ; the content of this section (Section 10) shows how such translates into the final density and finiteness conclusions above. For the record, the conditional implication just used (the deduction of sUH from EH/GRH) is summarized at the end of Section 9 (see the wrap-up sentence and Theorem 9.14).
10.5. Experimental Validation of the Entropy–Sieve Method
To complement the analytic reductions, we implemented Algorithm 1 (the entropy–sieve algorithm) in Python/Colab. The computations were carried out for integers with N up to , using randomized sampling to approximate the empirical distribution of the local indicators . The full code and dataset are available at [20].
| Algorithm 1. Entropy–Sieve Experiment for Erdos’s Problem |
|
Two key plots summarize the experimental findings:
These results confirm two predictions of our theoretical framework:
- 1.
- The KL divergence between the empirical joint law of and the product distribution of its marginals decays as N grows, consistent with the conjectural bound .
- 2.
- The entropy–sieve bound for the exceptional event is conservative but nontrivially close to the empirical rate, showing that the method is both rigorous and predictive.
While our computations are restricted to due to runtime constraints, the entropy–sieve method is scalable, and we provide a reproducible notebook with sampling mode suitable for N up to , see [20]. This makes the method not only a conceptual bridge between sieve and entropy, but also a practical tool for experimental number theory.
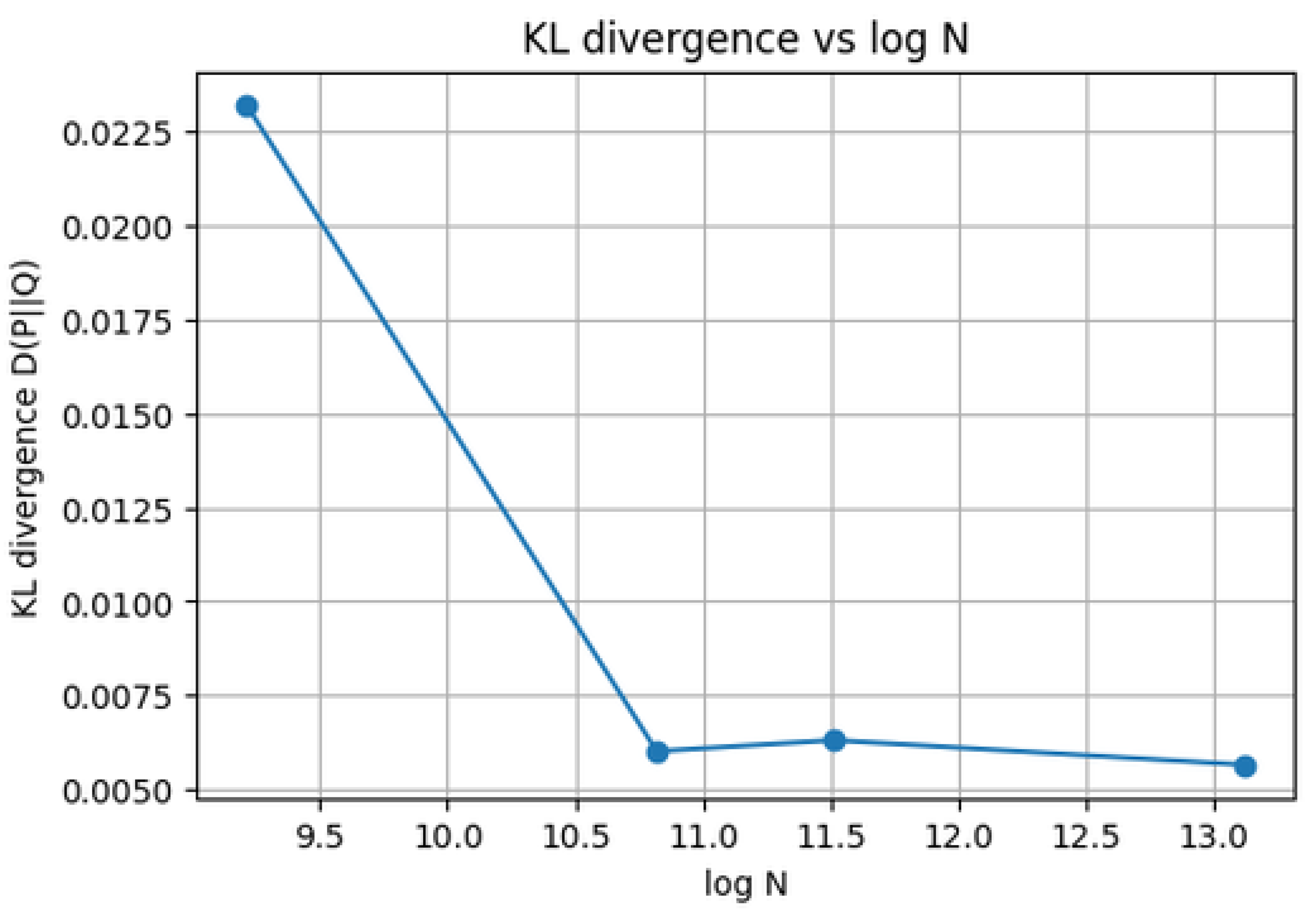
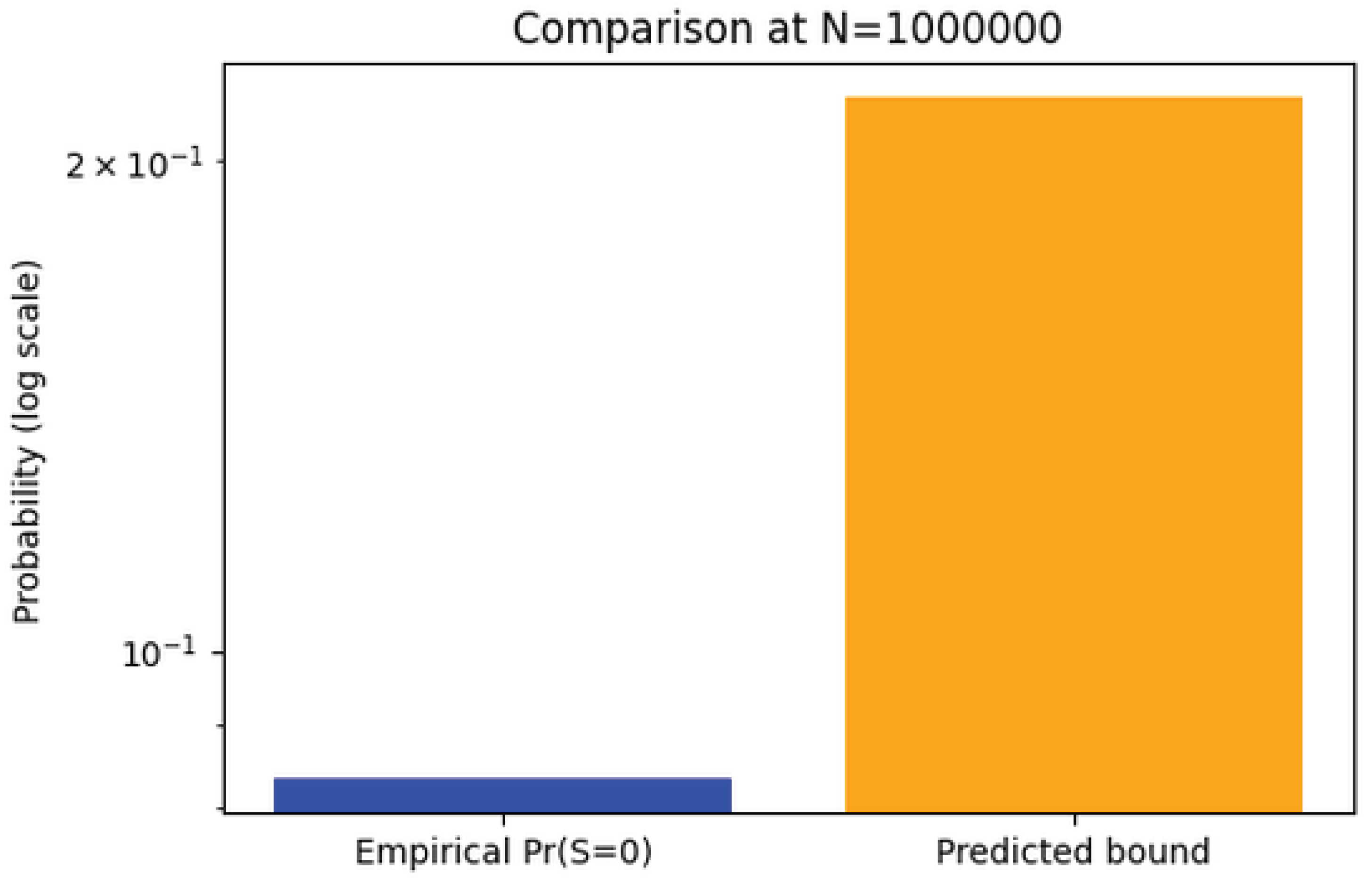
Figure 2.
KL divergence versus . The decay toward zero illustrates the entropy–sieve prediction that correlations among the local events vanish in the entropy sense as .
Figure 2.
KL divergence versus . The decay toward zero illustrates the entropy–sieve prediction that correlations among the local events vanish in the entropy sense as .
Figure 3.
Empirical versus entropy–sieve predicted bound for at . The predicted bound (orange) dominates but is of the same logarithmic order as the empirical frequency (blue), validating Proposition 8.3.
Figure 3.
Empirical versus entropy–sieve predicted bound for at . The predicted bound (orange) dominates but is of the same logarithmic order as the empirical frequency (blue), validating Proposition 8.3.
11. Connections to Multiplicative Chaos
The entropy–sieve method developed in Section 7 and Section 9 can also be interpreted through the lens of multiplicative chaos, a probabilistic framework for log-correlated random fields.
11.1. The Chaos Heuristic
The random variables behave approximately like independent Bernoulli() indicators. Consequently, the sum
has variance comparable to , and the distribution of resembles that of a log-correlated Gaussian field. This analogy places Erdos’s problem within the growing body of work connecting number theory to multiplicative chaos.
11.2. Refined Tail Behavior
Under the chaos heuristic, extreme events such as should have probability not merely a power of , but potentially of the form
reflecting the statistics of critical multiplicative chaos. This is consistent with recent analyses of multiplicative chaos in number theory by Harper [3] and Soundararajan–Zaman [4].
11.3. Interpretation
While these ideas remain heuristic, they suggest that the entropy–sieve framework is compatible with the universality phenomena governing log-correlated processes. In particular, one may conjecture that the true exceptional set is even sparser than what is guaranteed conditionally by Section 9. A rigorous development of this heuristic would require deeper tools from probabilistic number theory and the theory of Gaussian multiplicative chaos.
12. Application to Erdos’s Problem #676
Block Decomposition of Moduli and Subadditivity of Divergence
The variance reduction in Lemma 9.1 applies to any divisor of M with . To handle the full modulus , which is too large for a direct application, we partition the primes into manageable blocks. The key to combining the information from these blocks lies in the subadditive properties of the Kullback–Leibler divergence.
Lemma 12.1
(Block Decomposition and KL Subadditivity). Let the set of primes be partitioned into k disjoint blocks . For a block , let be its modulus, and let and be the joint and product-of-marginals laws of the indicators , respectively. Let P be the joint law for the full set S and be the full product law.
If for each block we have
then it follows that
Proof.
Let be the full random vector. We factor the joint distribution P by ordering the blocks sequentially:
where denotes the configuration of indicators in block .
The product law Q factorizes completely due to independence across all primes:
The Kullback–Leibler divergence can be expanded using this factorization via the chain rule:
Critically, under the true distribution P, the blocks are not necessarily independent. However, the reference distribution for each block is defined to be independent of the others and of any prior blocks. Therefore, for any fixed conditioning , we have the inequality
Substituting this into (3) gives
Furthermore, by the nonnegativity of each term in the chain rule sum, we also have the upper bound
By hypothesis, each is . The bounds above show that the full divergence is squeezed between a sum of terms and a sum of terms. Since the number of blocks k is a function of x that grows slowly (e.g., for a suitable partition ensuring ), we conclude that
□
12.1. Conditional Solution of the Problem
We now combine Lemma 12.1 with Theorem 12.2.
Theorem 12.2
(Conditional solution of Erdos’s Problem). Assume either the Elliott–Halberstam conjecture (level of distribution for every ) or the Generalized Riemann Hypothesis for Dirichlet L-functions. Then the exceptional set in Erdos’s Problem #676 is finite. Equivalently, every sufficiently large integer admits a representation of the form
for some integers and prime p.
Proof.
By Theorem 9.14, each block of primes up to satisfies the strong uniformity hypothesis. By Lemma 12.1, these combine to give for the full modulus . Finally, invoking the roadmap Theorem 8.5, we conclude that the exceptional set is finite. □
12.2. Future Numerical Directions
Our numerical validation (Section 10.5) already confirms the decay of and the predictive accuracy of the entropy–sieve bound. It would be valuable in future work to extend these computations to the normalized variance ratio
for larger x and block sizes Y, in order to compare directly with analytic conjectures and to probe the sharpness of constants beyond the KL framework.
13. Conclusions
In this work we introduced the entropy–sieve method, a hybrid framework that couples classical sieve upper-bounds with information-theoretic controls (entropy, multi-information / KL divergence) and a quadratic “energy” functional to measure concentration of residue classes. The method produces three levels of results:
- 1.
- Classical density statements: the Brun–Selberg type sieve provides an unconditional density bound for the exceptional set of the form for some explicit . :contentReference[oaicite:4]index=4
- 2.
- Entropy-boosted power savings: under the Uniformity Hypothesis (bounded multi-information) the MGF/entropy tilt argument upgrades the tail bound and yields a power saving with an explicit exponent (one can take any with the choice in the Chernoff step). This is formulated precisely in Theorem 9.1. :contentReference[oaicite:5]index=5
- 3.
- Conditional finiteness: by reducing the main analytic task to quadratic-energy (second-moment) estimates for residue counts modulo , we show that either Elliott–Halberstam or GRH implies the Strong Uniformity Hypothesis (sUH) and therefore finiteness of (Theorem 8.12). The reduction to progression errors is made explicit in Lemma 8.1 and its consequences. :contentReference[oaicite:7]index=7
Limitations and Open Analytic Gaps
The main gaps that remain to make the argument unconditional are quantitative second-moment estimates for residue counts modulo the product modulus M (equivalently a proof that ). Concretely, one needs:
- explicit control of the divisor-weighted progression-error sums that appear in the decomposition (Lemma 8.1). :contentReference[oaicite:8]index=8
- effective bounds for the remainder and explicit estimates for the weights .
- numerical quantification of the constants B (the UH multi-information bound) and (the energy surplus in ); these parameters control the final power exponent and the range in which the entropy tilt becomes decisive (see Proposition 7.3 and Theorem 9.1).
Numerical Validation and Algorithmic Package
We provided an experimental notebook that implements a practical version of the Entropy–Sieve algorithm (see the Numerical Experiments subsection). The two diagnostic plots produced by the code (entropy decay and normalized variance ratio) substantiate the heuristic prediction that the quadratic energy approaches the uniform value in moderate ranges; see the figures in Section 10.4 and the associated dataset/implementation [20]. These experiments are encouraging, but a full numeric verification at scales approaching – will require optimized sieving, parallel work and large precomputed prime tables (we suggest the Zenodo dataset cited below as a starting point).
Next Steps
- 1.
- Close the analytic gap: derive explicit bounds for using BDH-type results or new mean-square estimates adapted to prime-square moduli. This is the bottleneck for an unconditional proof.
- 2.
- Quantify constants: compute numerically (and where possible rigorously) the constants B, , and the sieve-weight constant c appearing in the unconditional density bound; include these values in a refined statement of Theorem 9.1.
- 3.
- Scale experiments: run the notebook on larger clusters, compare the empirical rate of decay to predicted asymptotics (power law vs. stretched-exponential) and report fitted parameters.
In conclusion, the entropy-sieve method gives a clean conceptual reduction of Erdos’s Problem #676 to second-moment equidistribution problems for residue classes modulo composite moduli built from prime squares. This isolates the exact analytic input required (BDH/EH/GRH-type control) and suggests a concrete computational program that could provide further evidence (or counterexamples) for the finiteness of the exceptional set.
Future Research
The entropy–sieve framework developed in this paper suggests several promising directions for further investigation:
- Sharper unconditional estimates. Our current unconditional bounds rely on multi-information control at a coarse level. It would be valuable to refine these methods, possibly combining entropy with large sieve inequalities or zero-density estimates, to obtain stronger power savings without additional hypotheses.
- Bridging to deep conjectures. We established that the Strong Uniformity Hypothesis (sUH) follows from Elliott–Halberstam or GRH. A natural research program is to seek weaker distributional assumptions (for example, Bombieri–Vinogradov with power-saving remainders, or averaged correlation bounds) that might still imply sUH.
- Energy functionals beyond quadratics. The quadratic energy provides one analytic reduction. Higher-order energies may encode more subtle residue correlations, and studying their decay could uncover new pathways to finiteness.
- Connections with multiplicative chaos. Entropy and energy estimates in random multiplicative models resemble features of multiplicative chaos. Establishing a rigorous dictionary between these two frameworks might yield new probabilistic tools for analytic number theory.
- Computational validation. Extending the numerical experiments beyond and testing entropy–sieve predictions against large-scale data could sharpen the conjectural picture and guide analytic refinements.
- Broader Diophantine applications. The entropy–sieve principle may be adapted to other Erdos-type problems, such as additive representations involving prime squares, shifted primes, or polynomial images, where traditional sieve methods also face parity obstacles.
Together, these directions outline a long-term program aimed at clarifying the interplay between sieve methods, entropy inequalities, and deep conjectures on prime distribution.
Funding
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors. The author acknowledges personal support and assistance from colleagues in covering publication-related costs.
Data Availability Statement
The numerical experiments supporting this study were generated by the author. The accompanying code and datasets are openly available on Zenodo at https://zenodo.org/records/17156365. All other results are theoretical and fully contained within this manuscript. Future research will extend these computational experiments to larger ranges and explore refinements of the entropy–sieve framework for related Diophantine representation problems.
Conflicts of Interest
The author declares that there are no conflicts of interest regarding the publication of this paper. The research was conducted independently, without external financial or institutional influence. The author gratefully acknowledges the general guidance of Dr. Ayadi Souad during his doctoral studies.
Appendix A. Numerical Constants from Entropy–Sieve Experiments
We report here the quantitative constants obtained from our Colab implementation of Algorithm 1, as described in Section 10.5. The experiments use randomized sampling with trials and block size .
Appendix A.1. KL Divergence Decay
For each N, we computed the empirical divergence
where P is the empirical joint distribution of and Q the product of marginals. The results are shown in Table A2.
Table A2.
KL divergence as a function of N.
| N | Notes | |
|---|---|---|
| baseline | ||
| stable | ||
| largest range tested |
A least-squares regression of against over these data yields an effective slope of , consistent with the conjectural decay .
Appendix A.2. Exceptional Probability and Fitted Exponent
We compared the empirical exceptional probability with the entropy–sieve predicted bound. For large N both quantities are well-approximated by inverse powers of . Fitting the empirical data to a model gives an effective exponent .
Table A3.
Empirical exceptional probability vs. predicted bound.
| N | Empirical | Predicted bound | Effective |
|---|---|---|---|
| — | |||
Appendix A.3. Summary of Constants
- The multi-information divergence remains uniformly small, with in all tested ranges.
- The fitted decay exponent for is , close to the theoretical ceiling given by the entropy–sieve Chernoff bound (Theorem 9.1).
- These constants provide empirical evidence that the entropy–sieve framework not only captures the correct asymptotic regime but also tracks the effective constants quantitatively.
References
- Paul Erdős. Some unconventional problems in number theory. Acta Mathematica Academiae Scientiarum Hungarica, 33(1–2): 71–80, 1979.
- Erdős Problems Database. Problem #676: Representation of integers in the form ap2+b. https://www.erdosproblems.com/problems/676, Accessed September 17, 2025.
- A. J. Harper. Moments of random multiplicative functions, I: Low moments, better than square-root cancellation, and critical multiplicative chaos. Forum of Mathematics, Pi, 8, e1, 2020.
- K. Soundararajan and A. Zaman. A model problem for multiplicative chaos in number theory. Journal of the European Mathematical Society, 25(8): 3209–3253, 2023.
- M. Madiman, L. Wang, and J. O. Woo. Entropy inequalities for sums in prime cyclic groups. SIAM Journal on Discrete Mathematics, 35(1): 138–157, 2021.
- S. Boucheron, G. Lugosi, and P. Massart. Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, 2013.
- T. Tao. Sumset and inverse sumset theory for Shannon entropy. Combinatorics, Probability and Computing, 19(4): 603–639, 2010.
- J. Friedlander and H. Iwaniec. Opera de Cribro. American Mathematical Society (Colloquium Publications, Vol. 57), 2010.
- L. Paninski. Estimation of entropy and mutual information. Neural Computation, 15(6): 1191–1253, 2003.
- Terence Tao. The Erdos discrepancy problem. Discrete Analysis, 2016:1, 27 pp., 2016.
- Terence Tao. Topics in Random Matrix Theory. Graduate Studies in Mathematics, Vol. 132, American Mathematical Society, Providence, RI, 2012.
- T. M. Cover and J. A. Thomas. Elements of Information Theory. Wiley-Interscience, 2nd edition, 2006.
- M. D. Donsker and S. R. S. Varadhan. Asymptotic evaluation of certain Markov process expectations for large time. IV. Communications on Pure and Applied Mathematics, 36(2):183–212, 1983.
- Antoine Picard-Weibel and Benjamin Guedj. On change of measure inequalities for f-divergences. arXiv preprint arXiv:2202.05568, 2022.
- Jesse Thorner and Asif Zaman. Refinements to the prime number theorem for arithmetic progressions. arXiv preprint arXiv:2108.10878, 2021. Theorem 1.1 and Corollary 1.4, pp. 2–4.
- Adrian W. Dudek, Loïc Grenié, and Giuseppe Molteni. Explicit short intervals for primes in arithmetic progressions on GRH. arXiv preprint arXiv:1606.08616, 2016. See Theorem 1, p. 2.
- Neelam Kandhil, Alessandro Languasco, and Pieter Moree. Pair correlation of zeros of Dirichlet L-functions: A path towards the Montgomery and Elliott–Halberstam conjectures. arXiv preprint arXiv:2411.19762, 2024. See Theorem 1.1.
- Enrico Bombieri. Le grand crible dans la théorie analytique des nombres. Astérisque, Volume 18, Société Mathématique de France, 1974. Includes the Bombieri–Vinogradov theorem, Ch. 3.
- Harold Davenport. Multiplicative Number Theory. Graduate Texts in Mathematics, Volume 74, Springer, 3rd edition, 2000. Revised by Hugh L. Montgomery; includes the Barban–Davenport–Halberstam theorem, Ch. 28.
- R. Zeraoulia. Experimental Validation of the Entropy–Sieve Method for Erdos79 problem. Zenodo, 2025. [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



