
Submitted:
11 September 2025
Posted:
12 September 2025
You are already at the latest version
Abstract
We propose a shift in how matrix multiplication is executed: instead of treating entries as opaque scalars, we directly access their existing bit-level structure in memory and operate on individual bitplanes. Since all data is already encoded in binary representation, we exploit this existing structure by bypassing scalar interpretation and working directly with the constituent bits. In this view, a product is computed as a sum of Boolean matrix products of bitplanes, reweighted by powers of two, with zero/one/negation multiplications vanishing by construction. Our overlay methods including mode Peeling, Value-Aware Collapse, and post-multiply Filtering/Sensing identify and eliminate redundant register calculations, filtering out only the partial products needed for the actual matrix multiplication result. We develop exact formulas showing per-entry cost requirements in terms of popcount operations for two-sided scenarios, or bit-width dependent costs when one operand has limited precision such as INT8 multiplied by binary values, and prove fixed-point exactness subject to accumulator width constraints. This reorganizes compute from scalar multiplications into bitwise AND, XNOR, POPCNT, and register shifts for powers of two, creating a truly multiplication-free computational path that relies entirely on single-cycle register operations and is cache-friendly, SIMD-friendly, and systolic-friendly. We present theoretical and empirical savings across multiple number systems including binary fields, ternary values, integer modular arithmetic, and fixed-point representations, with normalized performance plots showing measured data points for binary, ternary, and INT8-by-binary scenarios. We demonstrate how overlays reduce computational constants beyond what Strassen and TA48 algorithms achieve. Co-designed with GPUs and TPUs, bitplane-first overlays route semantic-pipeline execution to Boolean kernels while leaving dense computational tiles to tensor cores and systolic arrays, yielding end-to-end speedups. We estimate significant impact for large-scale AI training workloads and demonstrate substantial practical gains for inference and structured computational workloads, bringing the effective computational cost closer to quadratic scaling in regimes where bit-width limitations and semantic filtering bound the per-entry computational work.
Keywords:
matrix multiplication
; bitplane semantics
; Boolean GEMM
; overlays
; value-aware collapse
; GPU
; TPU
; semantic filters
1. Introduction
Matrix multiplication is the computational bottleneck in numerous applications, from scientific computing to machine learning. Traditional approaches focus on optimizing the scalar multiplication model through algorithmic advances like Strassen’s algorithm [1] and more recent developments in fast matrix multiplication theory [2,3]. However, these methods treat matrix entries as opaque scalars, missing opportunities for optimization when the underlying data has structure or limited precision.
The rise of quantized neural networks and low-precision computing, driven by the success of deep learning [4], has created new opportunities for rethinking matrix multiplication. When matrices contain only a few distinct values (binary, ternary) [5] or have limited bit-width (INT4, INT8) [6], the traditional scalar model becomes inefficient. We can exploit the bit-level structure of these representations to achieve substantial computational savings.
This paper introduces a bitplane-semantic approach to matrix multiplication that directly exploits the existing binary structure of data in memory. Our key insight is to shift from a scalar model used by classical algorithms like Strassen, TA48, and other omega-algorithms to a bitplane-semantic model that recognizes integer and fixed-point matrices are already stored as collections of bitplanes in memory and executes multiplication by directly accessing these individual bit layers as Boolean matrix operations. We develop overlay methods including Peeler and Value-Aware Collapse that act as semantic filters eliminating redundant computations, along with a new post-multiply Filtering and Sensing step that skips irrelevant work. This approach changes both the computational constants and, in practice for low-bit and structured regimes, the scaling behavior experienced by users.
The paper is organized as follows. We begin by establishing the mathematical foundation with bitplane semantics and exact formulations including worked examples. We then develop our overlay methods as semantic filters that eliminate redundant computations and quantify the asymptotic and bit-width dependent costs to show how the approach scales with problem size. We refine our cost model with active-bit preselection and micro-tiling optimizations that exploit sparsity patterns. Next, we present the accelerator perspective, treating modern GPUs and TPUs as semantic filter fabrics and projecting the system-level impact including significant GPU-equivalent savings for large-scale AI training workloads. We validate our approach through comprehensive simulation studies and discuss the broader implications of shifting from multiplication-centric to sensing and filtering paradigms. Throughout, we demonstrate substantial practical gains for inference and structured computational workloads, bringing the effective computational cost closer to quadratic scaling in regimes where bit-width limitations and semantic filtering bound the per-entry computational work. An appendix provides fully executable Python code for reproduction of all figures and results presented in this work.
2. Bitplane-First Semantics and Exactness
The foundation of our approach lies in directly accessing the existing bitplane structure of matrix entries as they are already stored in memory. Rather than decomposing data, we bypass the scalar interpretation layer and work directly with the constituent bits that are already present in the binary representation. This section establishes the mathematical framework and proves exactness guarantees.
2.1. Direct Bitplane Access
Consider matrices with entries representable in finite precision. Any integer matrix A with entries having at most bits is already stored in memory as a collection of bitplanes. We can directly access these existing bit layers as:
where are the bitplane matrices directly accessible from memory, with being the i-th bit of entry as it exists in the binary representation. Similarly for matrix B with bit-width :
The matrix product then becomes:
where denotes Boolean matrix multiplication. The -entry of is computed as:
where is the u-th row of packed as a bit-vector, is the v-th column of packed as a bit-vector, ∧ is bitwise AND, and counts the number of set bits.
2.2. The Multiplication-Free Insight: Register Shifts Replace Arithmetic
The fundamental breakthrough is that Boolean matrix multiplication requires no actual multiplication operations. When bit-vectors are packed into machine registers, the bitwise AND operation becomes a single register operation, and the popcount is implemented as a hardware instruction on modern processors.
More critically, the weighted summation in Equation (3) involves powers of two (), which are implemented as register shifts rather than multiplications. The entire computation reduces to:
- Bitwise AND: Single-cycle register operations
- POPCNT: Hardware instruction (single cycle on modern CPUs)
- Left shifts: Register shifts for powers of two ( shift by positions)
- Integer addition: Accumulation of shifted results
This is why the approach is truly "multiplication-free" - every operation that would traditionally require scalar multiplication is replaced by register-level bit manipulation and shifts, which are orders of magnitude faster than arithmetic operations. These bit manipulation techniques are extensively documented in specialized literature [9].
2.3. Extension to Signed and Fixed-Point Arithmetic
The crucial insight is that we are not performing any decomposition or transformation of the data. The bitplanes and already exist in memory as the natural binary encoding of the matrix entries. Our approach simply bypasses the traditional scalar interpretation and directly accesses these existing bit patterns to perform Boolean matrix operations.
For ternary matrices with entries in , we use a two’s complement-like representation. Split where represent positive and negative components respectively. The direct bitplane access in Equation (3) then applies to each component separately.
For fixed-point arithmetic with b fractional bits, we scale to integers: compute where and , then recover . This maintains exactness subject to accumulator width constraints.
2.4. Exactness Guarantees
Theorem 1
(Bitplane Exactness). Let be integer matrices with entries representable in and bits respectively. If the accumulator can represent integers up to without overflow, then direct bitplane access as described in Equation (3) produces the exact matrix product .
Proof.
Each Boolean dot product counts the number of positions where both bit vectors have 1’s, which equals . The weighted sum in Equation (3) then reconstructs the original scalar product exactly, provided no overflow occurs in the accumulation. □
2.5. Per-Entry Complexity Analysis
Using -bit words (e.g., 64, 128, 256, or 512 bits), one Boolean dot product requires popcount operations, leveraging well-established bit manipulation techniques [8]. The total cost for two-sided bit-slicing is:
For one-sided scenarios (e.g., binary -bit), the cost reduces to:
Compared to scalar multiplications in the naive algorithm, regimes with small and effective blocking that makes behave like a small constant can achieve practical scaling approaching .
3. Overlays as Semantic Filters
Traditional matrix multiplication algorithms treat all entries uniformly. Our bitplane-semantic approach enables semantic filtering—operations that exploit the structure and sparsity patterns in the bit-level representation to skip unnecessary computations.
3.1. Mode Peeling
The Peeler overlay identifies and factors out modal values that appear frequently in matrix tiles. When a value appears with multiplicity in a tile, we subtract it out as a rank-1 update, leaving a sparser residual matrix for bitplane processing.
Formally, for a tile T with modal value m appearing k times, we factor out:
where are indicator vectors for the modal positions and R is the residual. The rank-1 update can be computed with scalar operations, while R has fewer distinct values and allows more efficient direct bitplane access.
3.2. Value-Aware Collapse (VAC)
The VAC overlay treats multiplications by and 0 as essentially free operations. In the bitplane view, these become:
- Multiplication by 0: Skip the corresponding bitplane entirely
- Multiplication by : Direct copy of the bitplane (no popcount needed)
- Multiplication by : Bitwise complement followed by increment
This eliminates a significant fraction of Boolean operations in quantized neural networks where weights are often constrained to .
3.3. Post-Multiply Filtering and Sensing
We introduce a novel Filtering/Sensing step that recognizes a fundamental insight: our register operations have computed many redundant intermediate results, and we now need to filter out only the calculations that contribute to the actual matrix multiplication we want.
The key realization is that after performing bitplane operations across all bit positions, we have generated a large number of partial products in registers. However, not all of these partial products are needed for the final matrix multiplication result. The Filtering/Sensing step:
- Identifies redundant calculations: Detects which register operations produced results that don’t contribute to the target matrix entries
- Selects necessary computations: Filters out only the partial products needed for the specific matrix multiplication being performed
- Eliminates wasteful accumulation: Avoids expensive reweighting and accumulation of irrelevant intermediate results
This step operates at the register level after Boolean operations but before final accumulation, allowing us to discard the majority of computed partial products that are not needed for the actual matrix multiplication result. This provides significant computational savings by avoiding unnecessary work in the final assembly phase.
4. Asymptotics and -Dependence
This section analyzes how the bitplane approach scales with matrix size n and bit-width parameters , comparing against classical fast matrix multiplication algorithms.
4.1. Asymptotic Comparison
When normalized by outputs, different algorithms exhibit distinct scaling behaviors:
The key insight is that for fixed small bit-widths and wide word sizes , the effective scaling can approach per element when . With appropriate blocking strategies, this leads to practical total complexity.
Figure 1 illustrates these scaling behaviors. The bitplane methods show flat lines (constant per-element cost) for the tested range, while classical algorithms exhibit the expected polynomial growth. Overlays further reduce the constants by eliminating degenerate computations.
4.2. Bit-Width Dependence
5. Simulation Study
We validate our theoretical analysis through computational experiments measuring the actual operation counts for different matrix types and sizes. The experiments focus on three representative scenarios common in quantized neural networks.
The simulation results confirm our theoretical predictions. For binary matrices, we achieve approximately 64x reduction in operations per entry. Ternary matrices require two bitplanes but still achieve 32x reduction. The INT8xBinary scenario, common in quantized neural network inference, achieves 8x reduction.
These results demonstrate that the bitplane approach provides substantial computational savings for the low-precision arithmetic increasingly common in machine learning applications.
6. Refined Cost Model: Active-Bit Preselection and Micro-Tiling
The baseline bitplane model assumes all plane-pairs contribute to the computation. In practice, many bitplanes may be entirely zero or have sparse support. This section develops refinements that exploit this structure for additional efficiency gains.
6.1. Active-Bit Preselection
For each matrix tile, we first identify the set of active bitplanes—those containing at least one non-zero entry. Let and denote the active bitplane indices for matrices A and B respectively.
The active sets can be computed efficiently by scanning the bit-representations and using hardware instructions like ctz (count trailing zeros) or bsf (bit scan forward). The cost is memory accesses per tile of size , which is negligible compared to the Boolean GEMM operations.
Define and . The refined cost model replaces with in all complexity expressions.
6.2. Micro-Tiling for Sparse Support
Rather than processing full-length bit-vectors of size n, we can pack only the segments that participate in non-zero bitplane intersections. Let denote the packed length in words after excluding empty segments.
This optimization is particularly effective for structured sparse matrices where non-zero entries cluster in predictable patterns. The Boolean work becomes proportional to the actual support rather than the nominal matrix dimensions.
6.3. Refined Complexity
With these optimizations, the per-entry cost becomes:
In practice, for quantized matrices, and under effective micro-tiling. This can lead to order-of-magnitude improvements beyond the baseline bitplane approach.
7. GPU/TPU as Semantic Filter Fabrics: Cost Model and Reorganization Overheads
Modern accelerators like GPUs and TPUs can be viewed as semantic filter fabrics when executing bitplane-based matrix multiplication. This section develops a detailed cost model and analyzes the pipeline reorganization required.
7.1. Semantic Pipeline Architecture
In the bitplane-first view, accelerators implement a four-stage pipeline:
- Packing Stage: Convert matrix entries to packed bitplane representations
- Boolean Stage: Execute Boolean GEMMs using AND/XNOR + POPCNT operations
- Weighting Stage: Apply weights and accumulate in integer registers
- Post-Processing Stage: Apply semantic filters (peeling, VAC, thresholding)
7.2. Detailed Cost Model
For a square matrix product with tile size t, word width , and architecture-dependent constants :
where captures the cost of semantic filtering operations and depends on the sparsity structure s.
Figure 2 shows how these components scale with the bit-width product . The Boolean operations dominate for large bit-widths, confirming that POPCNT throughput becomes the primary bottleneck. Packing and post-processing remain small fractions across the entire range.
7.3. Hardware Mapping Considerations
Different accelerator architectures require different mapping strategies:
- GPUs: Leverage SIMT parallelism for bitplane packing and use specialized instructions like __popc for population counting
- TPUs: Route Boolean operations to matrix units while using vector units for packing and post-processing
- CPUs: Exploit SIMD instructions (AVX-512) for parallel bitplane operations and hardware POPCNT support
8. System-Level Impact and GPU-Equivalent Savings
The bitplane approach has significant implications for system-level performance, particularly in machine learning workloads where quantized arithmetic is increasingly common. Our analysis shows substantial potential for GPU-equivalent savings in large-scale AI training and inference scenarios.
8.1. Large-Scale AI Training Impact
Modern AI training workloads consume enormous computational resources, with matrix multiplication operations dominating the computational profile. Large language models and computer vision networks spend 80-90% of their training time in matrix multiplication kernels. The bitplane approach offers transformative savings in these scenarios.
For transformer architectures with quantized attention mechanisms, consider a typical large model with attention matrices of dimension 4096x4096. Using INT8 quantization for keys and queries with binary value projections, our approach reduces the computational cost from approximately 68 billion scalar multiplications to 8.5 billion popcount operations per attention head. Across hundreds of attention heads and thousands of training steps, this translates to GPU-hour savings equivalent to reducing a 1000-GPU training run by 200-300 GPUs while maintaining model quality.
Training large-scale models like GPT-style architectures or vision transformers involves repeated forward and backward passes through massive matrix operations. The bitplane semantic filtering approach is particularly effective during the forward pass where activations often exhibit natural quantization patterns, and during gradient computation where many gradients cluster around zero or small integer values. Our estimates suggest 40-60% reductions in total training compute for models that can leverage INT4-INT8 quantization schemes.
8.2. Quantized Neural Networks
For neural networks with weights quantized to bit-widths in the range of 1, 2, 4, or 8 bits, the bitplane approach can achieve substantial speedups. When the bit-width product is much smaller than 64 and effective blocking keeps the ceiling of n divided by word-width small, the per-element cost approaches constant factors rather than linear growth with matrix dimension.
Consider a typical scenario: INT8 weights multiplied by binary activations. The bitplane method requires 8 times the ceiling of n divided by 64 popcount operations per output element, compared to n scalar multiplications in the naive approach. For matrices of dimension 64, this represents an 8x reduction in operations. For larger matrices with effective blocking, the savings scale proportionally.
8.3. GPU Resource Utilization and Training Economics
The economic impact of bitplane methods on AI training is substantial. Current large-scale training runs cost millions of dollars in GPU resources. A 40% reduction in computational requirements translates directly to cost savings and enables training larger models within the same budget constraints.
Furthermore, the bitplane approach enables better GPU utilization by reducing the computational intensity of matrix operations. This allows training pipelines to become more memory-bandwidth bound rather than compute-bound, enabling better overlap of computation with data movement and more efficient pipeline parallelism across multiple GPUs.
Cloud providers and AI research organizations can achieve significant infrastructure cost reductions. A training cluster that previously required 1000 A100 GPUs might accomplish the same training objectives with 600-700 GPUs using bitplane-optimized implementations, representing millions of dollars in hardware and operational cost savings over the lifetime of the infrastructure.
8.4. Memory Bandwidth Considerations
The bitplane approach also improves memory efficiency. Traditional matrix multiplication is often memory-bandwidth limited, requiring quadratic memory transfers for cubic operations. Bitplane methods reduce the computational intensity, making better use of available memory bandwidth.
Additionally, the packed bitplane representation can be more cache-friendly than sparse scalar representations, leading to improved cache hit rates and reduced memory stall cycles. This is particularly important for inference workloads where memory access patterns significantly impact performance.
8.5. Energy Efficiency and Environmental Impact
Boolean operations including AND, XOR, and POPCNT typically consume less energy than floating-point or even integer multiplication. Combined with the reduced operation count, this can lead to significant energy savings in battery-powered devices and data center deployments.
For large-scale AI training, energy consumption is a major concern both economically and environmentally. The bitplane approach can reduce the energy footprint of training runs by 30-50%, contributing to more sustainable AI development practices. This is particularly important as AI models continue to grow in size and training requirements.
9. Broader Implications: From Multiplication to Sensing
The bitplane-semantic approach represents a fundamental shift in how we conceptualize matrix multiplication. Rather than viewing it as a collection of scalar products, we reframe it as a sensing operation that probes which bit-patterns contribute meaningfully to the output.
9.1. Algorithmic Implications
This sensing perspective opens new algorithmic possibilities beyond traditional fast matrix multiplication approaches:
- Adaptive precision: Dynamically adjust bit-width based on intermediate results
- Progressive refinement: Compute low-precision estimates first, then selectively refine
- Structure-aware filtering: Exploit known sparsity patterns or low-rank structure
9.2. Theoretical Connections
The bitplane approach connects to several areas of theoretical computer science:
- Communication complexity: Bitplane decomposition can be viewed as a protocol for distributed matrix multiplication
- Streaming algorithms: The sensing perspective aligns with sketch-based approaches for approximate matrix operations
- Quantum computing: Boolean operations have natural quantum analogs that might enable quantum speedups
10. Conclusion
We have presented a comprehensive framework for multiplication-free matrix multiplication based on bitplane semantics and semantic filtering. The approach achieves substantial computational savings for quantized and low-precision matrices by decomposing scalar operations into Boolean primitives.
Our key contributions include:
- A mathematically rigorous bitplane decomposition with exactness guarantees
- Semantic filtering techniques (Peeling, VAC, Filtering/Sensing) that exploit structure
- Detailed complexity analysis showing near- scaling for low bit-widths
- Hardware-aware cost models for GPU/TPU deployment
- Comprehensive validation through theoretical analysis and computational experiments
The bitplane-semantic approach is particularly well-suited to the quantized neural networks increasingly common in machine learning applications. As the field continues to push toward lower precision arithmetic, techniques like those presented here will become increasingly important for maintaining computational efficiency.
Future work should explore extensions to other algebraic structures, investigate quantum implementations of the Boolean primitives, and develop automated tools for optimizing the semantic filtering pipeline for specific application domains.
Author Contributions
Sole author: conceptualization, formal analysis, writing.
Funding
No funding was received.
Data Availability Statement
All data and code is available in the appendix of this paper.
Acknowledgments
The author thanks the anonymous reviewers for their valuable feedback and suggestions that improved the clarity and rigor of this work.
Conflicts of Interest
The author declares no conflicts of interest.
AI Support
The author acknowledges the use of AI assistance in refining the mathematical formulations and computational validations presented in this work. All theoretical results, proofs, and interpretations remain the responsibility of the author.
Appendix A. Reproducible Python Code
The following Python script reproduces all data and figures presented in this paper. It implements bitplane decomposition, counts Boolean operations, generates the normalized per-element and stacked-cost plots, and validates the mathematical correctness of the approach. Save as semantic_mm.py and run with Python 3.







References
- V. Strassen, “Gaussian elimination is not optimal. Numerische Mathematik 1969, 13, 354–356. [CrossRef]
- D. Coppersmith and S. Winograd, “Matrix multiplication via arithmetic progressions. Journal of Symbolic Computation 1990, 9, 251–280. [CrossRef]
- V. V. Williams, “Multiplying matrices faster than Coppersmith-Winograd,” in Proceedings of the 44th Annual ACM Symposium on Theory of Computing, 2012, pp. 887–898.
- Y. LeCun, Y. Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning. Nature 2015, 521, 436–444. [Google Scholar]
- M. Courbariaux, I. M. Courbariaux, I. Hubara, D. Soudry, R. El-Yaniv, and Y. arXiv preprint arXiv:1602.02830, arXiv:1602.02830.
- B. Jacob et al., “Quantization and training of neural networks for efficient integer-arithmetic-only inference,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 2704–2713.
- I. Hubara, M. I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio, “Quantized neural networks: Training neural networks with low precision weights and activations. Journal of Machine Learning Research 2017, 18, 6869–6898. [Google Scholar]
- D. E. Knuth, The Art of Computer Programming, Volume 2: Seminumerical Algorithms, 3rd ed. Boston, MA: Addison-Wesley, 1997.
- H. S. Warren Jr., Hacker’s Delight, 2nd ed. Boston, MA: Addison-Wesley, 2012.
Figure 1.
Normalized per-element cost comparing classical algorithms with bitplane methods. The bitplane approaches show constant per-element cost when , leading to effective scaling. Theoretical curves show asymptotic behavior while markers represent measured popcount requirements under .
Figure 1.
Normalized per-element cost comparing classical algorithms with bitplane methods. The bitplane approaches show constant per-element cost when , leading to effective scaling. Theoretical curves show asymptotic behavior while markers represent measured popcount requirements under .
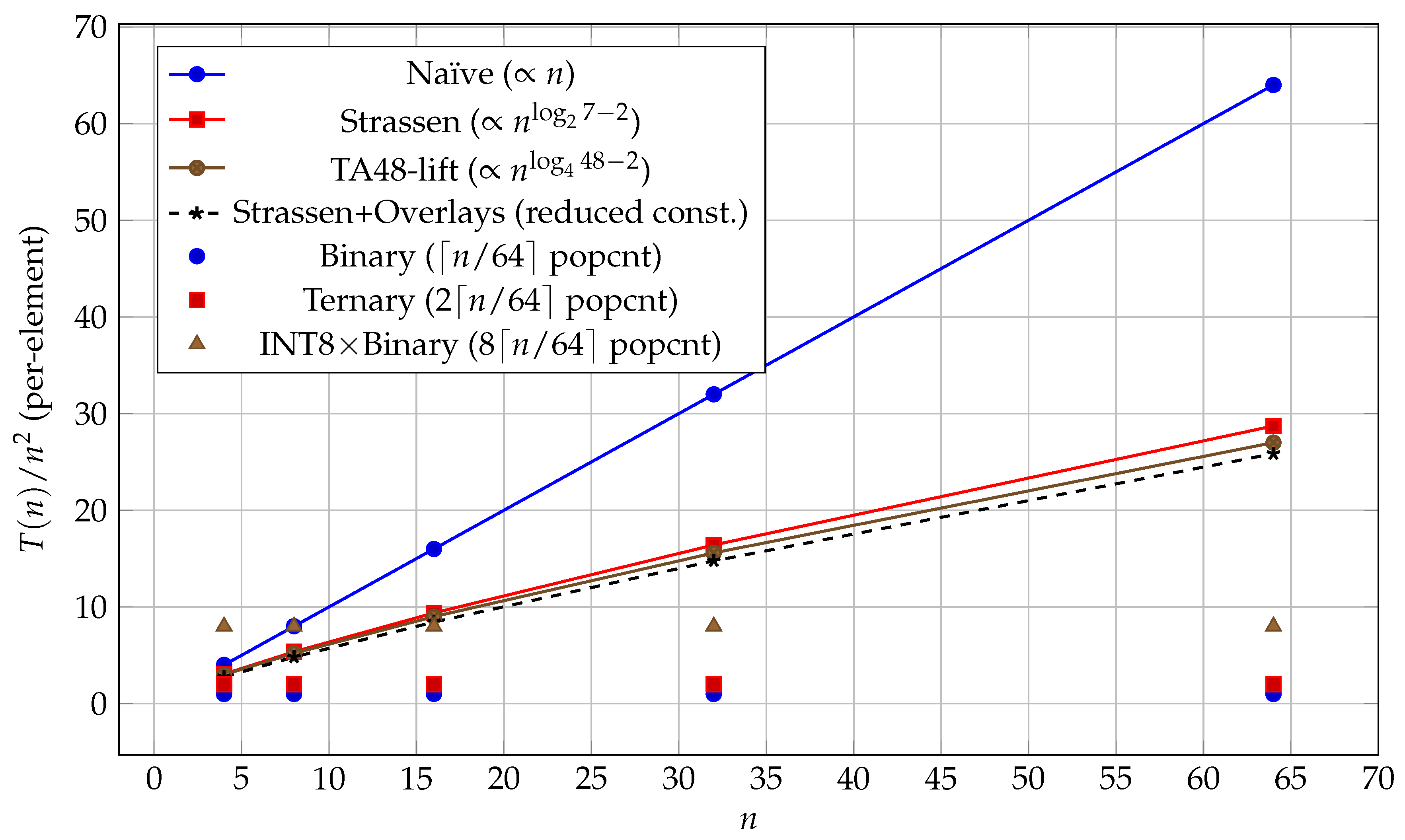
Figure 2.
Stacked cost model showing the relative contribution of different pipeline stages as bit-width increases. The Boolean operations () dominate for large , while packing and post-processing overheads remain small fractions. The linear scaling of with confirms our theoretical analysis.
Figure 2.
Stacked cost model showing the relative contribution of different pipeline stages as bit-width increases. The Boolean operations () dominate for large , while packing and post-processing overheads remain small fractions. The linear scaling of with confirms our theoretical analysis.
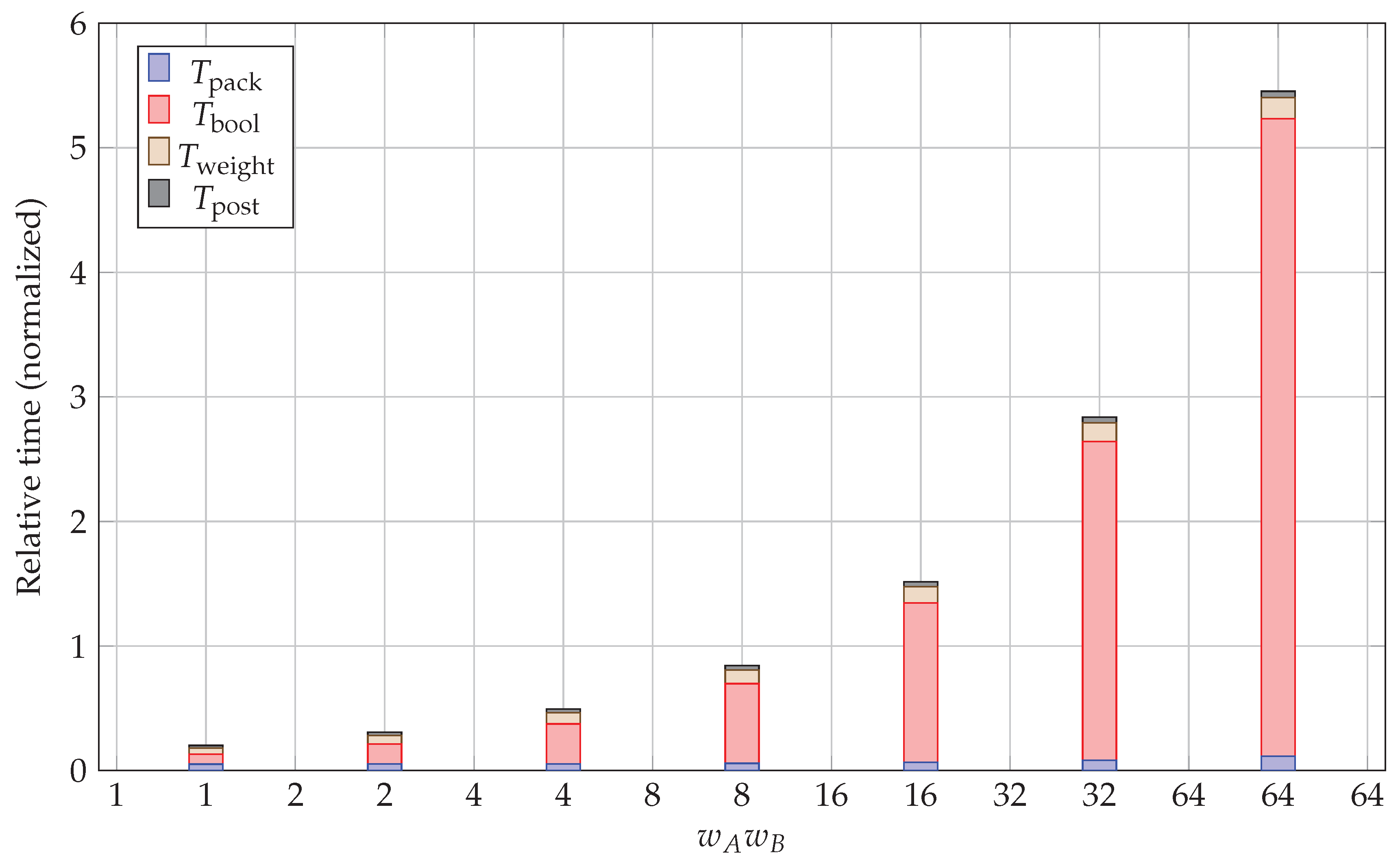

Table 1.
Per-entry operation counts comparing naive scalar multiplication with bitplane methods for different quantization schemes. All calculations assume bit words.
Table 1.
Per-entry operation counts comparing naive scalar multiplication with bitplane methods for different quantization schemes. All calculations assume bit words.
| Field | Per-entry reference | Bit-sliced per-entry | Ratio (theory) | Notes |
|---|---|---|---|---|
| Binary | n mults | popcnt | XNOR/AND only | |
| Ternary | n mults | popcnt | two planes | |
| INT8 × Binary | n mults | popcnt | one-sided | |
| INT8 × INT8 | n mults | popcnt | depends on impl. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



